
雷递智驾 乐天 3月18日
理想汽车自动驾驶技术研发负责人贾鹏今日在NVIDIA GTC 2025发表主题演讲《VLA:迈向自动驾驶物理智能体的关键一步》,分享了理想汽车对于下一代自动驾驶技术MindVLA的最新思考和进展。
贾鹏表示:“MindVLA是机器人大模型,它整合了空间智能、语言智能和行为智能,一旦跑通物理世界和数字世界结合的范式后,将有望赋能更多行业。MindVLA将把汽车从单纯的运输工具转变为贴心的专职司机,它能听得懂、看得见、找得到。我们希望MindVLA能为汽车赋予类似人类的认知和适应能力,将其转变为能够思考的智能体。”
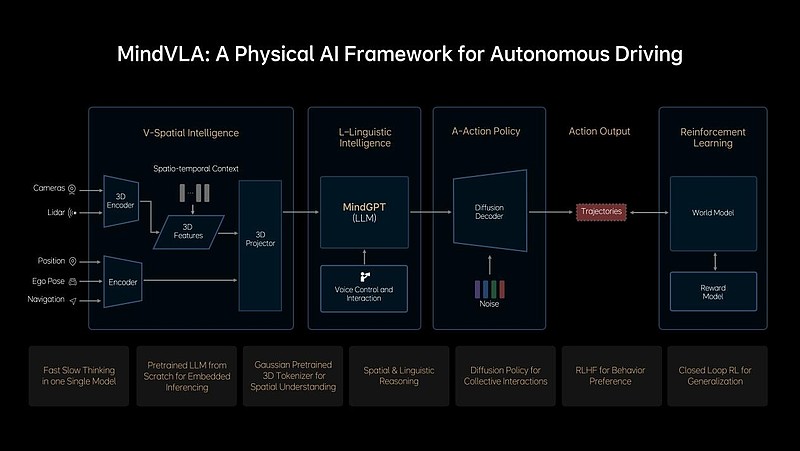
基于端到端+VLM双系统架构的实践,及对前沿技术的敏锐洞察,理想自研VLA模型——MindVLA。VLA是机器人大模型的新范式,其将赋予自动驾驶的3D空间理解能力、逻辑推理能力和行为生成能力,让自动驾驶能够感知、思考和适应环境。
MindVLA不是简单地将端到端模型和VLM模型结合在一起,所有模块都是全新设计。3D空间编码器通过语言模型,和逻辑推理结合在一起后,给出合理的驾驶决策,并输出一组Action Token(动作词元),Action Token指的是对周围环境和自车驾驶行为的编码,并通过Diffusion(扩散模型)进一步优化出最佳的驾驶轨迹,整个推理过程都要发生在车端,并且要做到实时运行。
MindVLA六大关键技术 树立新技术范式
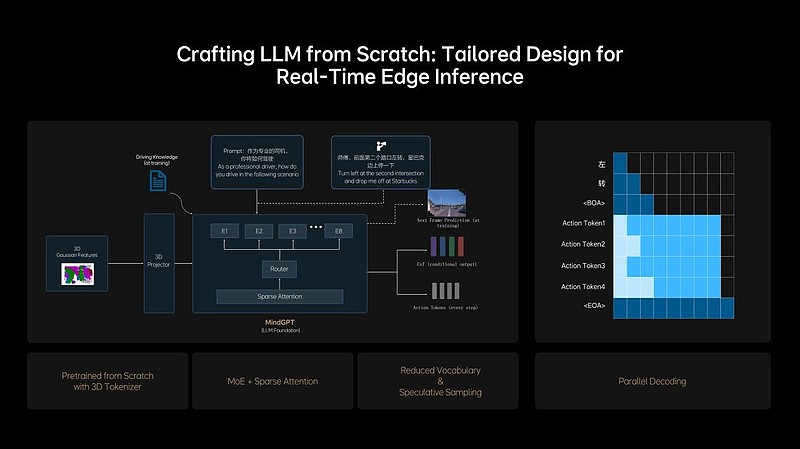
MindVLA打破自动驾驶技术框架设计的传统模式,使用能够承载丰富语义,且具备出色多粒度、多尺度3D几何表达能力的3D高斯(3D Gaussian)这一优良的中间表征,充分利用海量数据进行自监督训练,提升下游任务性能。
理想从0开始设计和训练适合MindVLA的LLM基座模型,采用MoE混合专家架构,引入Sparse Attention(稀疏注意力),实现模型稀疏化,保证模型规模增长的同时,不降低端侧的推理效率。基座模型训练过程中,理想加入大量3D数据,使模型具备3D空间理解和推理能力。
为了进一步激发模型的空间智能,理想加入了未来帧的预测生成和稠密深度的预测等训练任务。
LLM基座模型获得3D空间智能的同时,还需要进一步提升逻辑推理能力。理想训练LLM基座模型学习人类的思考过程,让快慢思考有机结合到同一模型中,并可以实现自主切换快思考和慢思考。为了把NVIDIA Drive AGX的性能发挥到极致,MindVLA采取小词表结合投机推理,以及创新性地应用并行解码技术,进一步提升了实时推理的速度。至此,MindVLA实现了模型参数规模与实时推理性能之间的平衡。
MindVLA利用Diffusion将Action Token解码成优化的轨迹,并通过自车行为生成和他车轨迹预测的联合建模,提升在复杂交通环境中的博弈能力。
同时Diffusion可以根据外部条件,例如风格指令,动态调整生成结果。
为了解决Diffusion模型效率低的问题,MindVLA采用Ordinary Differential Equation(常微分方程)采样器,实现了2-3步就能完成高质量轨迹的生成。面对部分长尾场景,理想建立起人类偏好数据集,并且创新性地应用RLHF(基于人类反馈的强化学习)微调模型的采样过程,最终使MindVLA能够学习和对齐人类驾驶行为,提升安全下限。
MindVLA基于自研的重建+生成云端统一世界模型,深度融合重建模型的三维场景还原能力与生成模型的新视角补全,及未见视角预测能力,构建接近真实世界的仿真环境。源于世界模型的技术积累与充足计算资源的支撑,MindVLA实现了基于仿真环境的大规模闭环强化学习,即真正意义上的从“错误中学习”。
理想汽车称,过去一年,理想自动驾驶团队完成了世界模型大量的工程优化,提升了场景重建与生成的质量和效率,其中一项工作是将3D GS的训练速度提升至7倍以上。
MindVLA赋能汽车变为专职司机
MindVLA将为用户带来全新的产品形态和产品体验,有MindVLA赋能的汽车是听得懂、看得见、找得到的专职司机。“听得懂”是用户可以通过语音指令改变车辆的路线和行为,例如用户在陌生园区寻找超市,只需要通过理想同学对车辆说:“带我去找超市”,车辆将在没有导航信息的情况下,自主漫游找到目的地;车辆行驶过程中,用户还可以跟理想同学说:“开太快了”“应该走左边这条路”等,MindVLA能够理解并执行这些指令。
“看得见”是指MindVLA具备强大的通识能力,不仅能够认识星巴克、肯德基等不同的商店招牌,当用户在陌生地点找不到车辆时,可以拍一张附近环境的照片发送给车辆,拥有MindVLA赋能的车辆能够搜寻照片中的位置,并自动找到用户。
“找得到”意味着车辆可以自主地在地库、园区和公共道路上漫游,其中典型应用场景是用户在商场地库找不到车位时,可以跟车辆说:“去找个车位停好”,车辆就会利用强大的空间推理能力自主寻找车位,即便遇到死胡同,车辆也会自如地倒车,重新寻找合适的车位停下,整个过程不依赖地图或导航信息,完全依赖MindVLA的空间理解和逻辑推理能力。
———————————————
雷递由媒体人雷建平创办,若转载请写明来源。

预售价32.99万起!1小时订单破9000!猛士M817以顶流华系技术突破越野边界
预售价32.99万起!1小时订单破9000!猛士M817以顶流华系技术突破越野边界
预售价32.99万起!1小时订单破9000!猛士M817以顶流华系技术突破越野边界
预售价32.99万起!1小时订单破9000!猛士M817以顶流华系技术突破越野边界
预售价32.99万起!1小时订单破9000!猛士M817以顶流华系技术突破越野边界
预售价32.99万起!1小时订单破9000!猛士M817以顶流华系技术突破越野边界
预售价32.99万起!1小时订单破9000!猛士M817以顶流华系技术突破越野边界
预售价32.99万起!1小时订单破9000!猛士M817以顶流华系技术突破越野边界

全家人的出行座驾,30万级选深蓝S09还是问界M8?

雷诺Sport Spider是法国雷诺汽车公司旗下雷诺运动部门在1996年至1999年间生产的一款纯粹主义跑车。这款车型的诞生背景可以追溯到1990年代初期,当时雷诺刚刚从1980年代后期的困难时期中走出,迫切需要一款能够彰显品牌运动基因的车型,就像十年前的雷诺5 Turbo那样......
预售价32.99万起!1小时订单破9000!猛士M817以顶流华系技术突破越野边界
预售价32.99万起!1小时订单破9000!猛士M817以顶流华系技术突破越野边界
预售价32.99万起!1小时订单破9000!猛士M817以顶流华系技术突破越野边界
预售价32.99万起!1小时订单破9000!猛士M817以顶流华系技术突破越野边界
预售价32.99万起!1小时订单破9000!猛士M817以顶流华系技术突破越野边界
预售价32.99万起!1小时订单破9000!猛士M817以顶流华系技术突破越野边界
预售价32.99万起!1小时订单破9000!猛士M817以顶流华系技术突破越野边界
预售价32.99万起!1小时订单破9000!猛士M817以顶流华系技术突破越野边界
预售价32.99万起!1小时订单破9000!猛士M817以顶流华系技术突破越野边界
预售价32.99万起!1小时订单破9000!猛士M817以顶流华系技术突破越野边界











































 京公网安备 11010102004670号
京公网安备 11010102004670号