
理想汽车负责自动驾驶的贾鹏在英伟达GTC做了一场名为“VLA:A Leap Towards Physical AI in Autonomous Driving(VLA:迈向自动驾驶物理智能体的关键一步)”的报告。30分钟的内容里面很详细地介绍了理想汽车目前在VLA上的进展,以及理想汽车是如何设计、训练全新的基座模型MindVLA,以及MindVLA现在呈现出的一些应用场景。
据此,理想汽车算是正式发布了下一代自动驾驶架构MindVLA,也或许会是汽车领域第一个接近于量产推送的VLA模型。
所谓VLA,就是视觉-语言-行动大模型,是一种多模态大模型,可以识别图像、语言,然后端到端输出行为。即便是放在全球来看,VLA也是目前各家AI企业争夺的下一颗明珠,特别是智能机器人企业更希望突破VLA,被视作“机器人大模型的新范式”。
只是汽车端的VLA比机器人更容易实现,毕竟汽车端的操作、控制维度要比类人机器人少许多,汽车只需要管加减速、左右方向,而类人机器人还有各种复杂操作。
所以,这次理想汽车首发MindVLA可以看作是在端到端智驾基础上一次全新升级,比现在各家正在不断追赶的单纯端到端更为领先,因为可以真正实现多模态。
实际上,在贾鹏的演讲里面,他比较简明扼要地介绍了为什么自动驾驶要做VLA。
“其中之一就是为了应对复杂而多样的公交车道。确实,除了到处乱窜的电动车和高强度的人车博弈外,中国的道路结构本身也足够复杂。为了提升出行效率,公交车道被广泛使用。然而各地的标识方法和使用规则非常多样,采用了比如地面的文字标识,空中指示牌或者路边高标牌。
同时会以不同的文字形式说明这些车道的时段限制。这些多变的规则和文字表达为自动驾驶带来了巨大的挑战。”贾鹏解释说,虽然可以用先验信息或者地图来解决,但是中国道路情况变化太快,包括各种道路地面标识的变更,其实都无法用先验信息来解决。

而且公交车道只是阻挡中国智驾发展的其中一个问题,其余还包括动态可调的可变车道和潮汐车道,也增加了如待转区,待行区。这些都让单纯的端到端智驾无法在城区高效运行,也是我们在智驾测试中遇到的普遍问题。
为了解决这些问题,理想汽车在去年推出了一个22亿参数规模的视觉语言大模型VLM,在需要文字理解能力常识和逻辑推理的场景中,VLM会通过思维链CoT进行复杂的逻辑分析,给出驾驶决策并指挥快系统去执行。这也就是理想汽车现在讲的端到端+VLM的智驾模型,而且也在被很多友商的智驾或多或少借鉴。
但是,贾鹏认为端到端+VLM实际投入量产之后,也发现了以下四类问题:
1、虽然理想汽车可以通过异步联合训练,让端到端和VLM协同工作,但由于它们是两个独立的模型,而且运行于不同的频率,整体的联合训练和优化是非常困难的。
2、理想的VLM模型是基于开源大语言模型训练的,里面海量的互联网二级图文数据做预训练,但是在3D空间理解和驾驶知识方面是有所不足的。
3、自动驾驶芯片如Orin-X和Thor-U它的内存带宽和算力是不及服务器GPU的,限制了模型的参数量和能力提升,也不能实现高效推理。
4、驾驶行为的学习更多的依赖于transformer进行回归建模,但这种方法难以处理人类驾驶行为的多模态性。
结合上述四点问题,理想汽车的解决方案是,端到端模型和VLM模型合二为一,同时学习像GPT o1和DeepSeek R1一样,利用思维链的方式让模型自己学会快慢思考,同时赋予模型强大的3D空间理解能力和行为生成能力。
这也就是理想汽车发布的VLA模型MindVLA。而理想汽车官方将其解释为:“VLA是视觉语言行为大模型,它将空间智能、语言智能和行为智能统一在一个模型里,VLA是Physical AI的最新范式,它赋予自动驾驶这样的物理系统感知思考和适应环境的能力。”
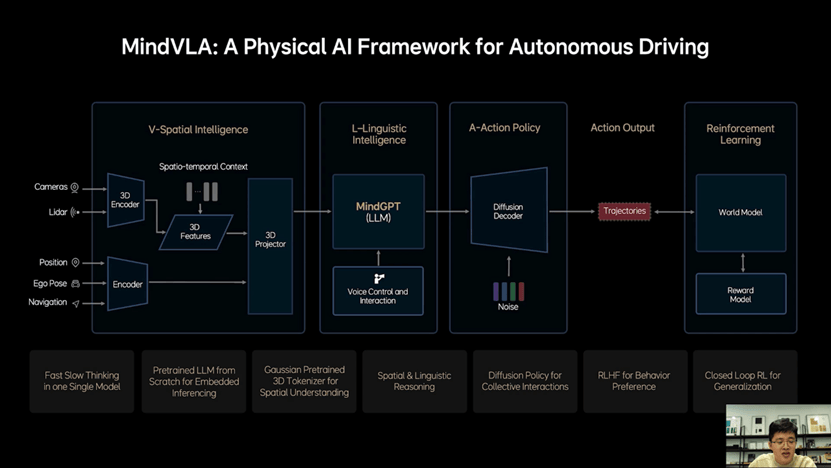
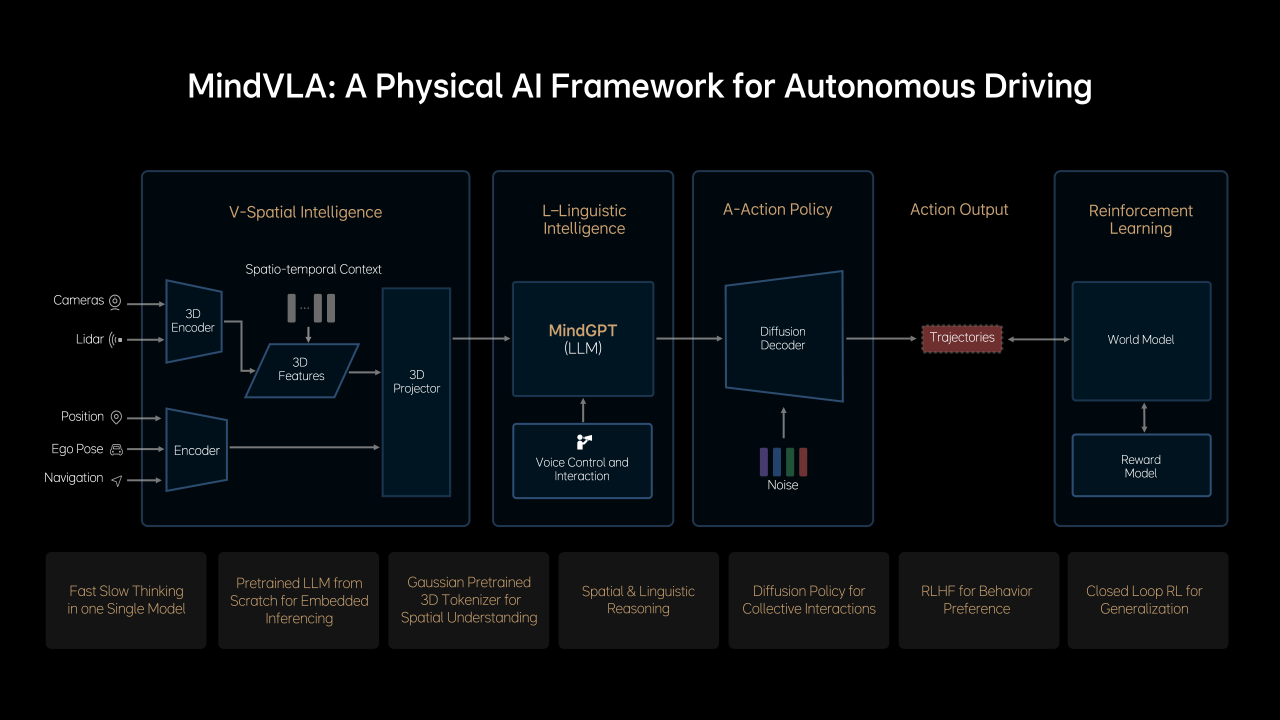
关于MindVLA模型,首先要知道的是,理想智驾工程团队没有简单地把端到端和VLM两个模型直接揉在一起,而是所有的模块都全部重新设计。
“3D空间编码器通过语言模型和逻辑推理结合在一起后给出合理的驾驶决策,并输出一组Action token,最终通过diffusion进一步优化出最佳的驾驶轨迹。这里所谓的Action token是对周围环境和自车驾驶行为的编码,整个模型推理过程都要发生在车端,而且要做到实时运行。”贾鹏解释了这张图的逻辑。
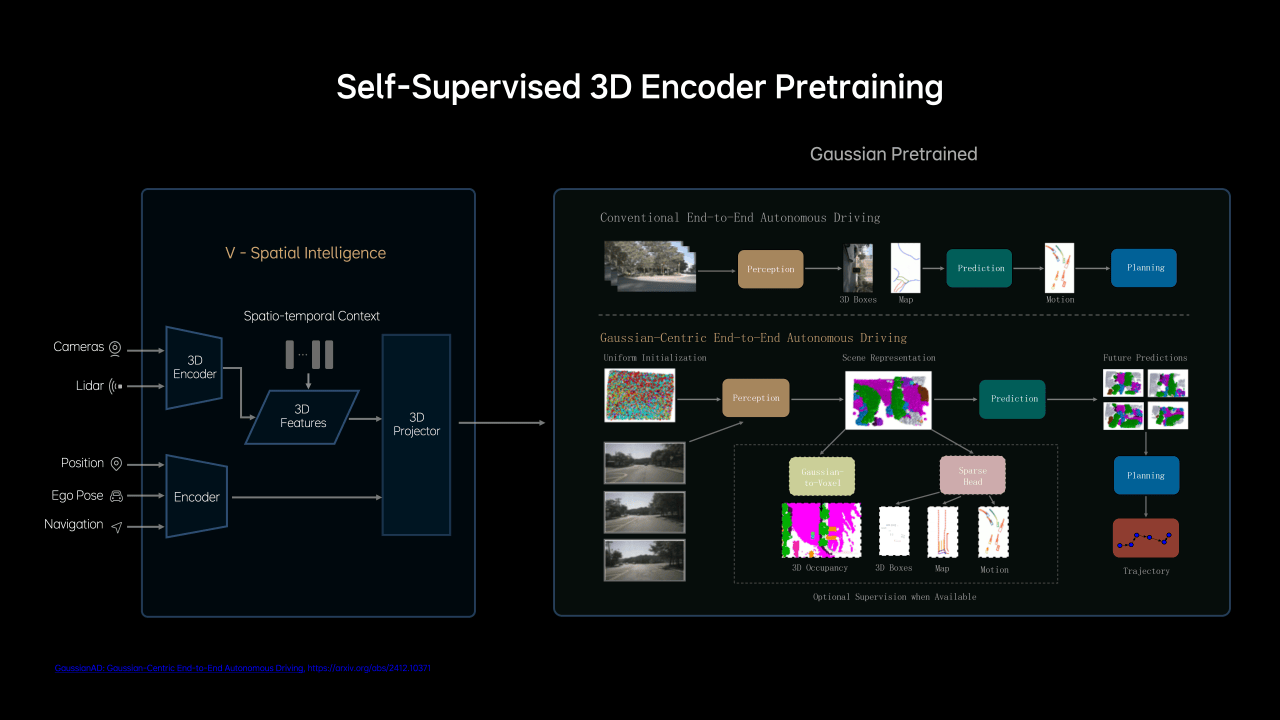
从这张图可以看到,摄像头和激光雷达传感器是直接输入到3D空间编码器,再结合时空上下文转换为3D特征,而位置信息、自车姿态、导航信息输入到常规编码器,两者合一传递到3D Projector进一步将特征映射到特定空间,比如BEV。这一模块就被称为3D空间智能模块,也就是Vision的部分。
接下来的L-Linguistic Intelligence就是语言智能。这一块是和之前端到端+VLM完全不同的地方,之前是VLM读出来之后传递给端到端系统做判断,而现在MindVLA则是输出3D表征到特定空间之后,让理想自己训练的大语言模型MindGPT去理解这些空间信息,然后做出判断、进行行为指令输出。
这里的指令输出按照理想汽车的解释会有两种模式:一个是慢输出,也就是CoT思维链思考过后的结果;一种是快输出,不经过思维链直接输出Action token。
这里还有一个能力是,增加了语音控制和互动的能力,是直接把指令给到大语言模型,然后模型会自动拆解任务,再结合3D空间智能进行Action token输出。
在Action这一步,理想汽车还加入了Diffusion模型,这里可解释为理想汽车的MindVLA借助Diffusion模型不仅生成自车的轨迹,还预测其他车辆和行人的轨迹,大大提升了标准模型在复杂交通环境中的博弈能力。
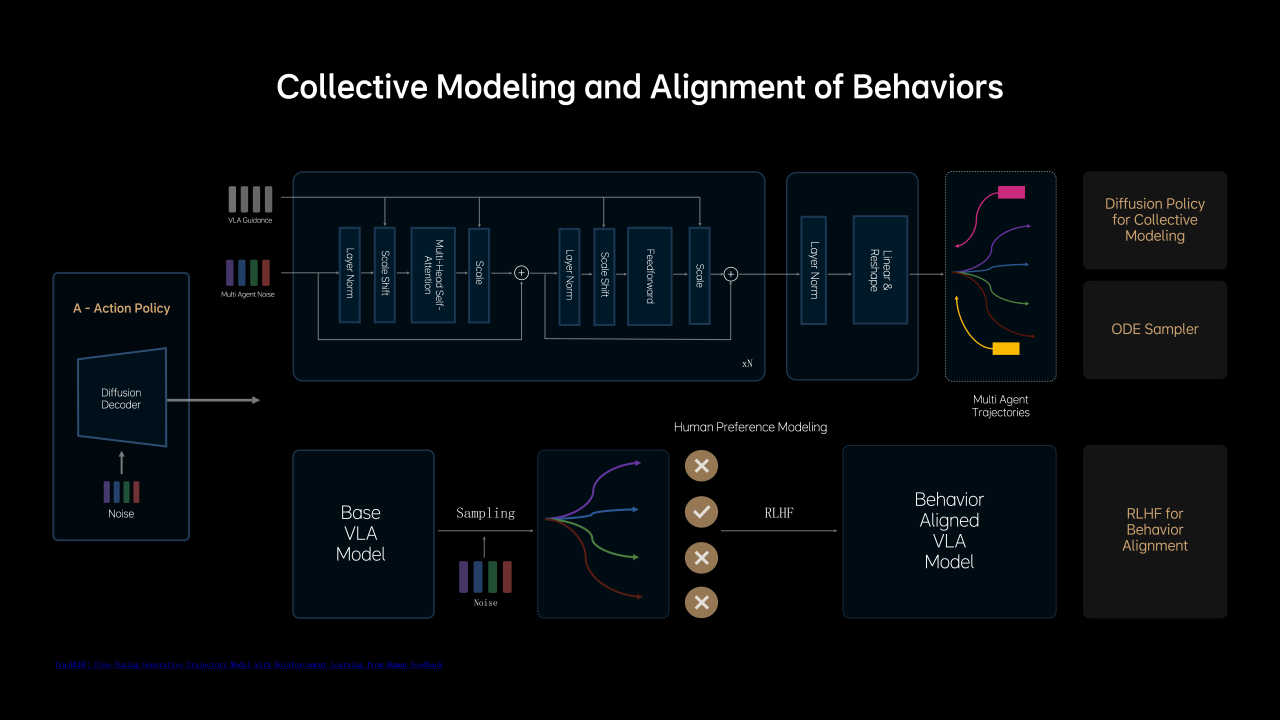
并且Diffusion还有一个巨大的优势,是可以根据外部的条件输入改变生成结果——如果你使用过AI生成图片就知道,漫画风格、写实风格是可以有不同参数指令来控制——这时候你就可以要求MindVLA有不同的驾驶风格,比如开快点、开慢点、激进一点、保守一点等等,而不会像现在的端到端可能就只有一种风格。
以上就基本解释了理想MindVLA模型的架构和训练逻辑,显然它是一个比端到端+VLM更加先进、更加拟人、并且还带有时空预测能力的全新智驾模型。
但是这其中要解决的工程问题也很多,技术要点理想没有展开,只是谈到了几个技术突破:
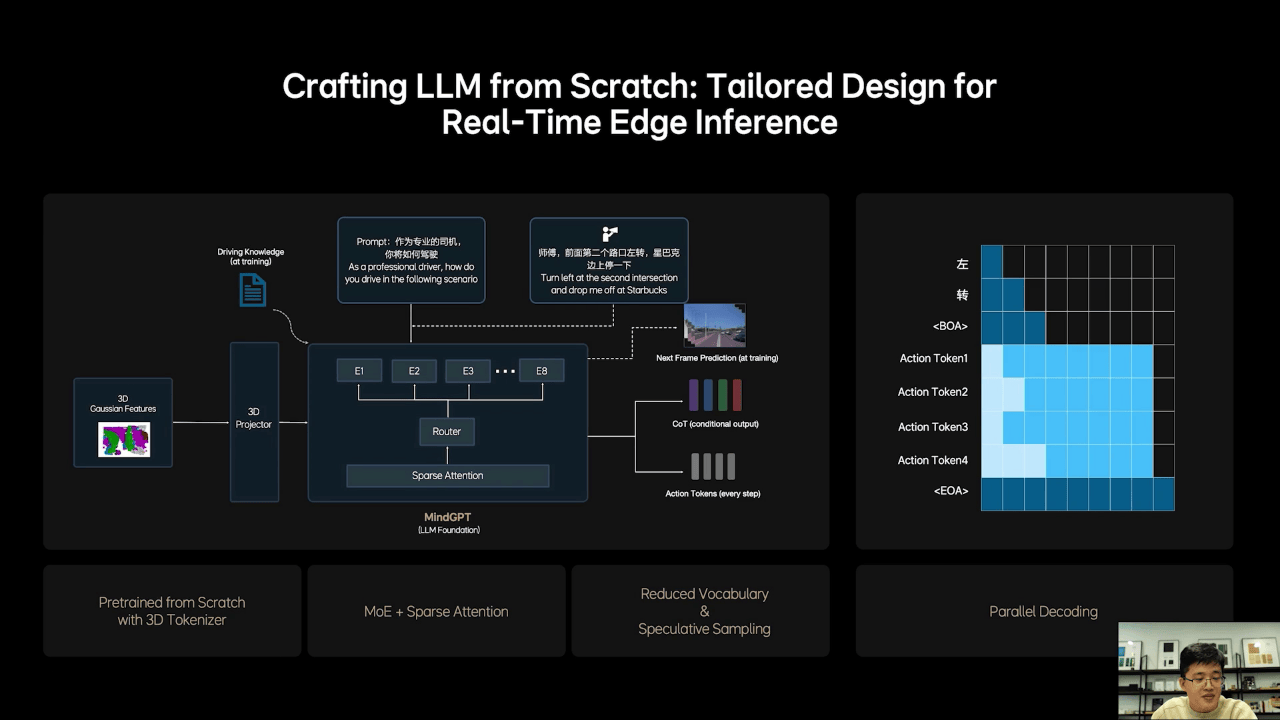
1、不同于之前依赖监督学习的BEV+占用网络3D表征,理想MindVLA使用了3D高斯(3D Gaussian)这一优良的中间表征,可以实现自监督训练,极大提升了下游任务性能。
2、理想从0开始设计和训练了适合MindVLA的LLM基座模型,采用MoE混合专家架构,引入Sparse Attention(稀疏注意力),实现模型稀疏化,保证模型规模增长的同时,不降低端侧的推理效率。
基座模型训练过程中,理想加入大量3D数据,使模型具备3D空间理解和推理能力,减少了文史类数据的比例。为了进一步激发模型的空间智能,理想加入了未来帧的预测生成和稠密深度的预测等训练任务。
3、训练模型去学习人类的思考过程,并自主切换快思考和慢思考。在慢思考模式下,模型会经过思维链CoT再输出Action token,由于自动驾驶不需要冗长的CoT,同时也因为实时性的要求,所以理想使用了固定且简短的CoT模板。
4、在Orin-X和Thor-U的性能基础下,理想采用了小词表和投机推理,大幅提升CoT的效率,实现了VLA超过10赫兹(也就是每秒10次)的推理速度。理想还采用了创新性的并行解码的方法,也就是在同一个阐述方法模型中加入了两种推理模式:语言逻辑的推理,通过因果注意力机制逐字输出;而Action token则采用双向注意力机制一次性全部输出。
5、为了解决Diffusion模型效率低的问题,MindVLA采用Ordinary Differential Equation(常微分方程)采样器,实现了2-3步就能完成高质量轨迹的生成。面对部分长尾场景,理想建立起人类偏好数据集。
6、创新性地应用RLHF(基于人类反馈的强化学习)微调模型的采样过程,最终使MindVLA能够学习和对齐人类驾驶行为,显著提升安全下限。
不过理想也没有止步于模型架构本身,贾鹏在演讲中说,他们也希望让系统有机会超越人类驾驶水平、也就是达成自动驾驶的能力。
他的观点基本上和目前做L4的企业一样,单纯的强化学习并没有特别好的效果。第一是因为早期的生成架构未能实现端到端的可训,强化学习作为一种稀疏的弱监督过程,若无法实现高效的无损的信息传递,强化学习的效果就会大打折扣。
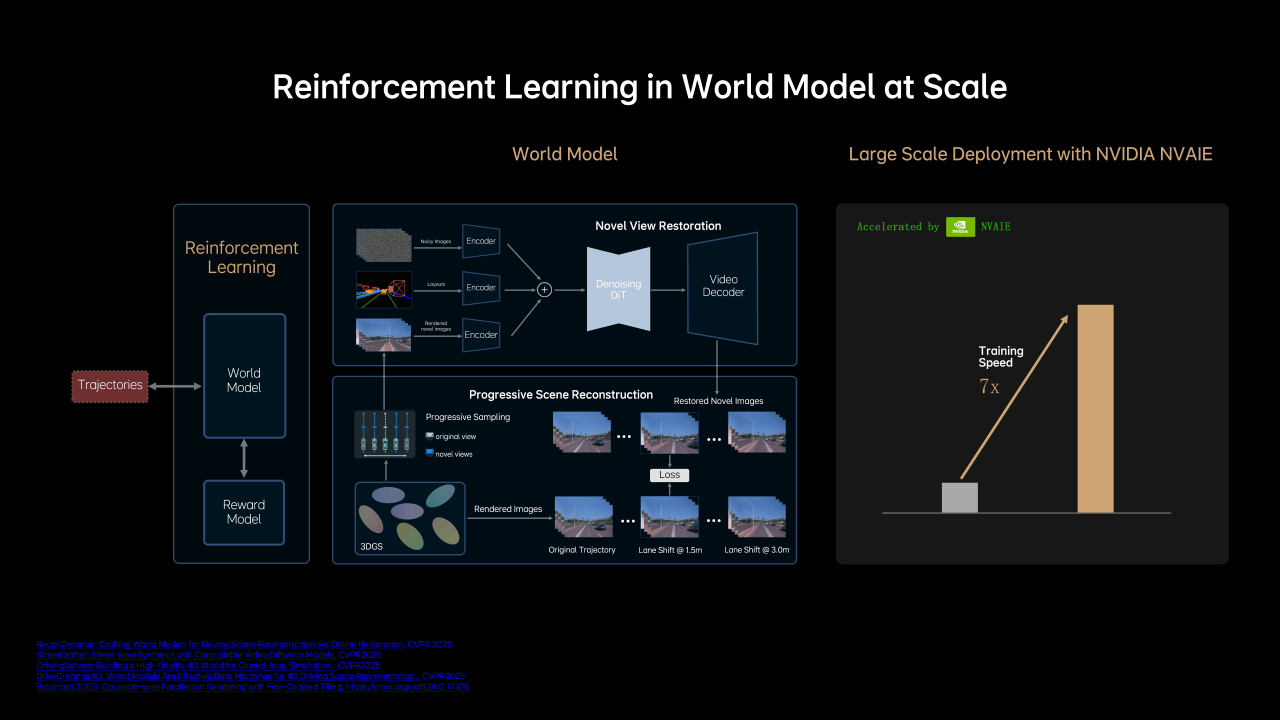
第二,Physical AI需要与真实世界进行交互,以获取奖励信号,因此自动驾驶作为Physical AI最直接的应用,它的强化学习也高度依赖于高度仿真的交互环境,但是之前都是3D游戏引擎、真实性不足。理想汽车推出的MindVLA可以说是解决了第一个限制,而第二个限制则需要更真实的3D环境。
所以理想汽车也透露,MindVLA基于自研的重建+生成云端统一世界模型,深度融合重建模型的三维场景还原能力与生成模型的新视角补全,以及未见视角预测能力,构建接近真实世界的仿真环境。过去一年,理想自动驾驶团队完成了世界模型大量的工程优化,显著提升了场景重建与生成的质量和效率,其中一项工作是将3D GS的训练速度提升至7倍以上。
按照理想汽车上述说法,那就意味着理想在世界模型的建立上也取得了突破,或许不会比蔚来前几天传出的世界模型更慢。并且理想汽车表示,MindVLA已经实现了基于仿真环境的大规模闭环强化学习,即真正意义上的从“错误中学习”。
最终的结果就是,理想通过创新性的预训练和后训练方法,让MindVLA实现了卓越的泛化能力和涌现特性,其不仅在驾驶场景下表现优异,在室内环境也展示出了一定的适应性和延展性。
同时,理想汽车也用三个场景来展示了全新的MindVLA模型带来的用户端体验——
第一个场景是驾驶者可以直接用模糊指令“我要去星巴克”,让车辆在没有启动智驾路线的前提下实现车辆的漫游寻找,也能用“开慢一点”来指挥车辆降速,最终通过摄像头识别来确认抵达星巴克门口。这个多模态的场景是最符合VLA的应用。
第二个场景是通过拍摄到的图片来寻找用户的位置。基本逻辑是通过收到图片后分析图片特征,然后从地下停车场出发,来到地面后经过漫游来寻找到用户。视频展示的过程还是很流畅,但是个人猜测实际使用过程中可能会需要一些照片的位置信息来判断,不太可能只依靠于图片场景。

第三个场景是车库漫游停车。驾驶员下车之后,车辆完全自主寻找停车位,也可以应对断头路等等场景,这个场景其实和VPD差别不大,区别可能在于VPD需要首先扫描停车场,而理想MindVLA则是可以完全在陌生停车场执行。

实际上,通过理想汽车发布的几个演示可以看到,这些场景都是实现了L4级别的自动驾驶,第二、第三个场景完全是处于无人驾驶状态完成了,这或许也是VLA架构带来的巨大飞跃。
毫无疑问,在端到端智驾如雨后春笋般涌现的今天,理想汽车发布的MindVLA自动驾驶架构直接向着L4又迈进了一大步,跨过了高速L3的这个阶段,也拉开了和友商的距离。这应该也就是理想在年初那场AI对话中提到的一些畅想的落地,只是现在要看VLA的训练结果,以及在真实场景中VLA比端到端的具体细节优势有哪些。
图片及文字资料来源:
理想TOP2《理想贾鹏英伟达GTC讲VLA 1228字省流版/完整图文/完整视频》
理想汽车《理想汽车发布下一代自动驾驶架构MindVLA》
(END)

9月27日下午,极狐北京地区交付仪式在北汽蓝谷正式启动,北汽集团副总经理、北汽极狐董事长张国富等多位公司经营层领导来到现场,为首批极狐T1车主送上车钥匙、交车礼盒和大运河音乐节门票

快3平台聊天室计划【—3 3df· VIP—】 师Q→6027-331 导【—5 5df· VIP—】【大发购彩网】【亏损包赔】【精准计划】【导师带赚钱】【彩票平台】【万人聊天室】
大发导师一对一精准计划【—33DF· VIP—】【—44DF· VIP—】【企鹅:6027331】新车频道,为您提供最新2025新车资讯[AZU],包括新车发布新闻、新车动态资讯、



大发金牌导师的稳准计划誷纸:DF965.CC】【誷纸:DF970.cc】【大发购彩网】【亏损包赔】【精准计划】【导师带赚钱】【信誉平台】【万人聊天室】【老玩家首选】【福利多多】GD

9月25日,比亚迪第二代秦PLUS双车上新,发布了秦PLUS DM-i 128KM进取型、秦PLUS EV 420进取型、510KM进取型等三款新车,同时全系车型享国庆献礼价,限时
大发聊天室精准计划【—3 3df· VIP—】 师Q→6027-331 导【—5 5df· VIP—】【大发购彩网】【亏损包赔】【精准计划】【导师带赚钱】【彩票平台】【万人聊天室】

腾势N8L正式开启预售啦,预售价31.98万元起!作为一台大六座安全豪华SUV,它从设计、空间到智能配置,全都围绕“家”来打造,真正做到了“全家三代人的满意之选”。外观延续了腾势家
快3平台聊天室计划【—3 3df· VIP—】 师Q→6027-331 导【—5 5df· VIP—】【大发购彩网】【亏损包赔】【精准计划】【导师带赚钱】【彩票平台】【万人聊天室】

国庆假期有买SUV车型的打算?这期视频盘点了近期上市的新热SUV车型,看它没错

9月25日,长安汽车正式推出全球车型——第四代CS55PLUS,新车共发布4款配置,叠加现金优惠后售价7.89万元起,并有多重购车礼遇。第四代CS55PLUS价格权益的发布,使其成

大发人工精准回本稳定计划群【—DF970· CC—】【—DF952· CC—】 新车频道[也曾多情向边疆],为您提供最新2025新车资讯[AZU],包括新车发布新闻、新车动态资讯、
大发聊天室精准计划【—3 3df· VIP—】 师Q→6027-331 导【—5 5df· VIP—】【大发购彩网】【亏损包赔】【精准计划】【导师带赚钱】【彩票平台】【万人聊天室】



大发导师一对一带赚回本【—33DF· VIP—】【—44DF· VIP—】【企鹅:6027331】新车频道,为您提供最新2025新车资讯[AZU],包括新车发布新闻、新车动态资讯、
快3带赚计划平台【—3 3df· VIP—】 师Q→6027-331 导【—5 5df· VIP—】【大发购彩网】【亏损包赔】【精准计划】【导师带赚钱】【彩票平台】【万人聊天室】【
幸运快3金牌导师计划【—33DF· VIP—】【—44DF· VIP—】【企鹅:6027331】新车频道,为您提供最新2025新车资讯[AZU],包括新车发布新闻、新车动态资讯、八
大发聊天室精准计划【—3 3df· VIP—】 师Q→6027-331 导【—5 5df· VIP—】【大发购彩网】【亏损包赔】【精准计划】【导师带赚钱】【彩票平台】【万人聊天室】

9月26日,腾势汽车全新大六座安全豪华SUV——腾势N8L正式开启预售,预售价31.98万至34.98万元。作为与科技安全旗舰SUV腾势N9一脉相承的家庭豪华伙伴,腾势N8L与腾势

碧海映金秋,潮起赋新程。9月29日,“40万级中型旗舰电混SUV”2026款星途瑶光C-DM寰球版在奇瑞集团青岛超级工厂正式上市。作为基于M3X超混平台打造的战略车型,瑶光C-DM


































 京公网安备 11010102004670号
京公网安备 11010102004670号