作者 |肖恩
编辑 |德新

中国农历新年结束没多久,马斯克就给中国的特斯拉车主送上一份大礼——2月26日,在毫无征兆的情况下特斯拉向中国区购买了FSD的HW4.0车主开启了功能推送。
此前一度传言FSD因为数据问题入华时间将推迟,而且这次推送的是和美国相同的V13版本,对于它在中国的表现大家非常好奇,随后各大媒体和大V都对FSD进行了详细的测试。
从媒体的测试结果来看,FSD的表现无疑是不及格的,认错路和违反交规是常规操作,甚至用接管次数这个指标已经无法评价它的表现了,要用违章次数才能体现出FSD在中国的拉跨,中国智驾遥遥领先的声音更响亮了。
但是FSD的表现真的如此不堪吗?
一、端到端架构:特斯拉智驾指明的方向作为智驾从业者,我也体验了FSD在城区的表现。
如果以接管次数为评价指标,FSD和国内第一梯队的方案相比,确实是不合格的,但是几乎所有的接管都是和交通规则和道路相关。这也侧面印证了马斯克的说法,现阶段由于数据问题特斯拉只能通过互联网的视频来训练FSD,无法很好地理解和适应中国的交通环境。
除此之外,FSD的基础能力堪称惊艳,异常流畅的控制、行云流水的绕行、果断的超车和变道,给人的体验就像是经验丰富的专车司机,在遇到拥堵情况时决策毫不拖泥带水。
从我个人的体验来看,FSD如果适应了中国的交规和道路,它的表现将超过国内现阶段的智驾方案。
特斯拉从V12开始全面转向端到端架构,和之前的版本相比FSD的表现有了巨大的提升,从BEV、Transformer到占用格栅网络。在传统的感知-规划-控制的架构下,特斯拉给智驾行业带来了非常多的启示,为了实现无人驾驶的目标,特斯拉跳出传统的思维框架,第一次在量产车上引入了端到端的架构,为智驾行业指出了新的技术方向。
也许是怕中国学生学得太快,特斯拉并没有公布自己端到端架构的细节。
国内智驾行业开始自己探索端到端这条技术路径,其中最典型和成功的案例,无疑是理想的端到端+VLM双系统架构。这个方案将理想从原来智驾第三梯队的位置快速提升至第一梯队,在部分场景的表现甚至超过华为的ADS。
理想的这套系统结合了快慢系统的理论。
系统1是一段式的端到端模型,可以处理95%以上的常规驾驶场景;同时为了提升长尾场景的处理能力,引入了VLM视觉语言模型作为系统2辅助决策,系统2能够对场景进行描述和分析,给系统1提出决策建议。
其中VLM的核心是一个LLM模型,也就是类似chatGPT的大语言模型。它有非常强的理解和逻辑推理能力,由大规模海量互联网数据预训练的LLM具备一定的通识认知,能够利用符合逻辑的推理能力获得复杂场景和从未见过的长尾场景的处理能力。
理想在LLM的基础上,使用了车辆的传感器数据和场景描述信息对模型进行了训练,最终让VLM模型能够对场景完成思维链推理,从场景描述到场景分析,最终完成层级规划并输出轨迹。
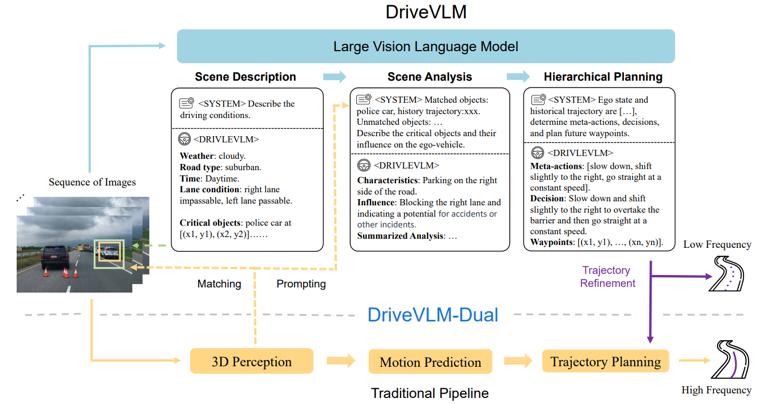
从实际的体验来看,这套系统「端味十足」,对车辆的控制非常线性,驾驶行为接近人类的习惯,VLM的加入让系统在特殊场景下的表现也可圈可点,是当前技术条件下非常好的思路。
但是,这套系统仍然有一些问题要解决。
第一个问题就是VLM系统的延时太高。
由于LLM模型的参数量非常大,对于计算量的需求很高。现在车端算力最大的智驾芯片OrinX也只有254Tops,虽然经过非常多的优化,最终VLM在车端能实现的频率也只有5Hz左右,无法满足实时性的要求,导致VLM的决策轨迹只能作为决策建议,并不能直接输出给车辆控制,在一定程度上限制了VLM的能力。
第二,理想的VLM基座模型是千问。
它是阿里的开源大语言模型,这一类模型基于网络上大量的文本训练而成,特点是通用性好,有很强的对语义理解能力和对话能力,但并不是专为驾驶场景设计。对于驾驶行为的理解能力有限,也没有很好的3D空间理解能力,即使经过了训练,但是上限不够。
第三,端到端和VLM是两个独立的模型,使用的训练数据也不相同,而且运行的频率不一样,对两个模型联合训练和优化非常困难。
为了解决这些问题,理想给出的答案是VLA。
二、什么是VLA?VLA代表Vision-Language-Action,最早出现在具身机器人领域。
谷歌DeepMind在2023年7月发布了全球首个可以控制机器人的VLA模型:RT-2,这个模型以大语言模型为基础,模型接收摄像头的原始数据和语言指令后,可以直接输出控制信号,完成各种复杂的操作。

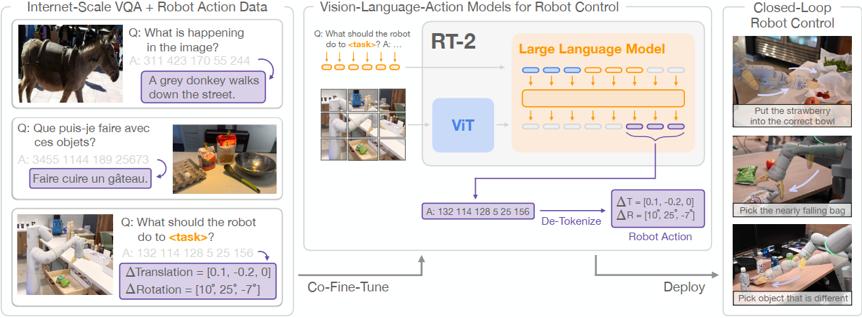
RT-2的结构非常简单,图像信息经过VIT编码后和语言信息的token一起输入到LLM中,谷歌在这里使用了自家的Gemini,模型输出一系列的Action token,解码后转化为机械臂的控制信号。
和以前的模型相比,RT-2在交互能力、任务能力和泛化能力上都有非常大的提升。
传统的机器人模型只能支持少数的特定指令,借助于大语言模型强大的语言理解能力,RT-2可以直接和用户进行语言交互,能够理解复杂和模糊的指令,完成各种类型的任务。
大语言模型最强大的地方在于它的泛化能力,基于互联网海量信息的训练,大模型会涌现出强大的通识能力,这就是我们常说的Scaling Law,这种能力可以迁移到VLA模型中,能够让模型理解训练数据以外的物体和场景。
VLA在机器人领域的成功,很快也应用在了自动驾驶上。
不论是传统的规则模型还是数据驱动的端到端模型,都无法解决一个问题。如果某个场景在模型的训练数据之外,系统的表现会非常不稳定,只能不断修补,但是现实中驾驶场景太复杂,没有办法在数据中穷举所有的可能。因此长尾场景一直是自动驾驶最大的挑战。
自从大语言模型出现后,它表现出接近于人类水平的理解能力,给工程师看到一种可能,利用大模型来解决长尾场景,VLM和VLA都是这个方向的探索。
继RT-2之后,24年11月一直专注于L4方案的Waymo发布了用于自动驾驶的多模态大语言模型(Multimodal Large Language Models)EMMA,虽然Waymo没有将其定义为VLA,但是从模型的结构看,可以看作是VLA的一种形态。
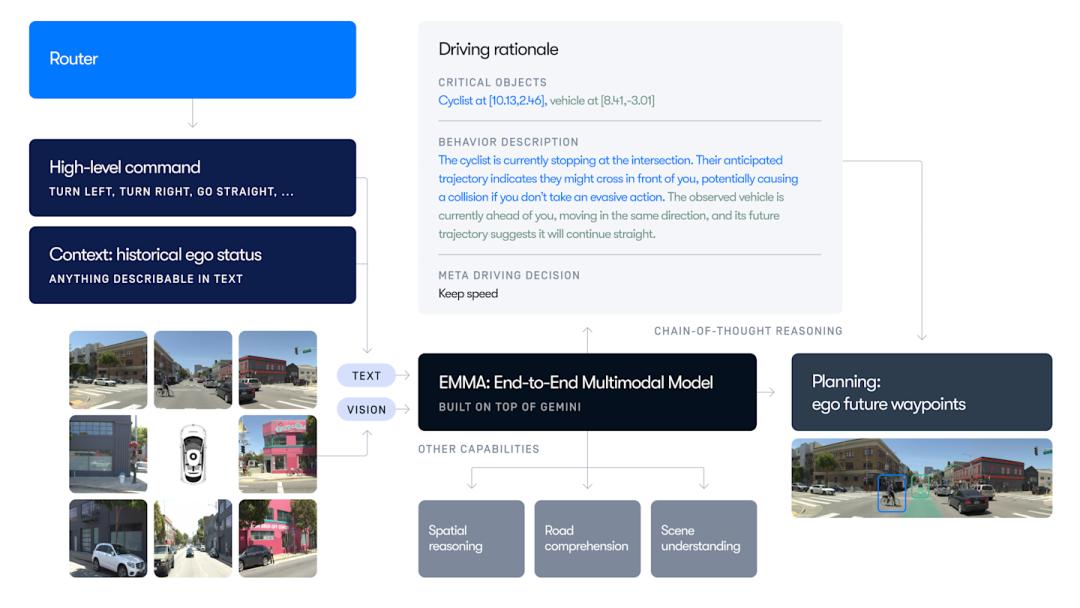
EMMA有三个输入,分别是
摄像头的原始图像;导航的路径信息;历史信息和自车状态。中间的大语言模型和RT-2一样,基于谷歌的Gemini,通过CoT思维链的推理,EMMA能输出以下信息:
自车未来的轨迹;感知结果;道路元素;对场景的理解。在nuScenes数据集的Planning Benchmark上,EMMA的表现经验,超过了传统端到端模型,如UniAD以及许多VLM模型,侧面证明了VLA在自动驾驶领域的潜力。
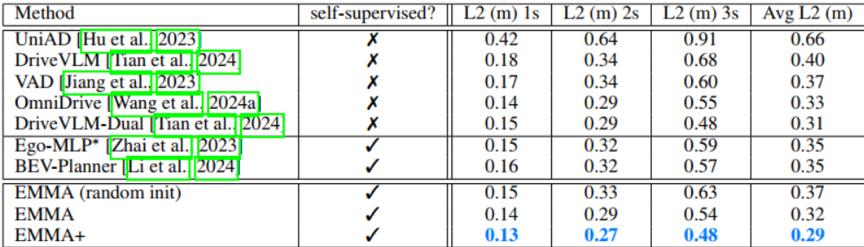
虽然EMMA也有一些问题,例如对于3D空间的推理能力较弱、计算量大等,但是为自动驾驶带来的新的方向。
三、VLA上车难,难在哪里?虽然EMMA和DriveGPT4等VLA模型在学术领域都取得了不错的进展,但是至今还没有一个可量产的方案出现,这里有几个问题要解决。
算力问题
不论哪种VLA都是基于大语言模型来实现,而大语言模型的特点除了参数量大之外,对算力的要求非常高,通常都是部署在服务器端。
目前车端的自动驾驶芯片算力非常有限,量产算力最高的自动驾驶芯片OrinX也只有254Tops,这限制了车端能部署的模型规模以及运行的频率。
从理想VLM的经验来看,虽然经过了非常多工程上的优化,最终的运行效率仍然达不到10Hz,需要更强大的芯片来支持。英伟达下一代的Thor U芯片将超过700 Tops,对于VLA上车来说会是非常重要的一环。
数据闭环
另一个对VLA非常重要的挑战是数据。
虽然大语言模型已经基于海量的互联网数据进行训练,对于语言和文本已经有了非常强的分析能力,但对于驾驶相关的视频数据、激光雷达点云和车辆状态等数据,并没有公开的海量数据可用。
而且VLA的关键能力CoT思维链,需要根据设计的逻辑和问题建立定制化的数据,需要车企有非常强的数据闭环能力。
在现在全民智驾的背景下,很多OEM喜欢用汽车的保有量来宣称自己有海量的数据,能够快速迭代智驾算法,实际上这只是面向普通消费者的宣传术语。
即使是软件和硬件架构高度统一的特斯拉,前几代产品产生的数据也很难对现在的算法有帮助,更别说国内的OEM早期的车辆基本只有一颗前视摄像头,而且方案还五花八门,这种数据对于高阶智驾的算法,特别是VLA而言就是毫无用处。
进入端到端和VLA的时代,数据闭环不仅仅是收集数据,收集什么样的数据,如何从海量的量产数据中挖掘有用的场景,如何把这些场景用在算法的优化上;谁能更早把这些问题想清楚,谁就能在数据为王的时代占得先机。
可解释性差
这几乎是所有大语言模型的通病。虽然大模型能够涌现出强大的能力,但是它似乎是一个大的黑盒子,到现在也没有人能很好地解释为什么大模型会有Scaling Law,以及它是如何思考的。也许对于语言类的大模型而言,逻辑上的错误并不致命,但是对于自动驾驶来说,一个小小的错误有可能就会产生严重的后果。
因此可解释性对于自动驾驶而言是非常重要的特性,特别是在量产车上,遇到有问题的场景,需要找到根源问题root cause才能快速地优化。
虽然在VLA中增加了对于决策过程的解释,但是无法像传统算法那样定位到问题代码,如何快速解bug,这会是VLA上车之后的一大挑战。
办法总比困难多,虽然VLA上车有种种挑战,但是总用不怕困难的厂商率先尝试,这一次还是理想走在了前面。
四、打响VLA上车的第一枪作为首发VLM上车的车企,理想无疑是去年智驾行业最耀眼的明星。
不到一年的时间,理想再次领先一步,3月18日理想正式发布了下一代自动驾驶架构MindVLA,这是一个融合了视觉、语言和行为智能的大模型,赋予了自动驾驶强大的3D空间理解能力、逻辑推理能力和行为生成能力,让自动驾驶能够感知、思考和适应环境,更重要的是通过3D高斯、MoE混合专家架构的LLM基座模型和diffusion模型等技术,让VLA第一次应用在量产车。
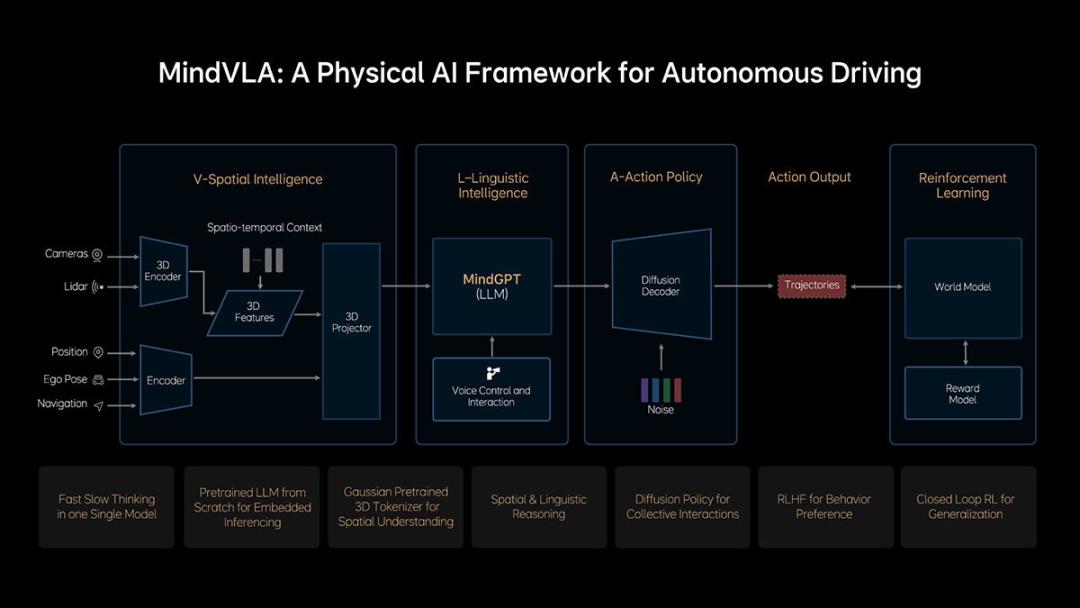
理想也公开了非常多的细节,从架构上看MindVLA和学术领域的VLA架构有很多的不同点。
之前的VLA架构非常简单,输入是传感器数据和语言信息,输出轨迹,中间是一个大的基座模型,而MindVLA除了有基座大模型之外,还增加了其它的模块,这其中有几个关键的技术,代表了理想从工程端对VLA的理解。
V - Spatial Intelligence空间智能
在MindVLA的架构中传感器数据没有直接输入到基座大模型中,而是先经过了一个V-Spatial Intelligence的模块,这个模块能根据传感器的原始输入形成对3D物理世界的理解,和大语言模型相比,有更强的空间感知能力,这其中关键的技术是使用了3D高斯表征。
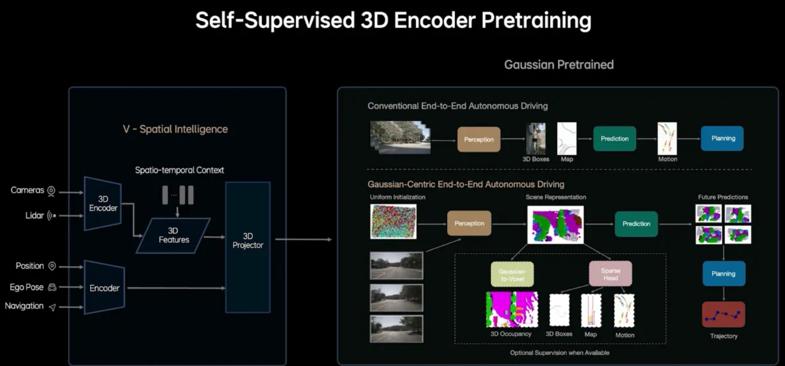
3D高斯最早起源于图像渲染和三维场景重建领域,可以通过二维的图像还原3D的场景,此前该领域广泛应用的是神经辐射场算法-NeRF,这是一种基于辐射场和光纤可逆原理还原3D物体的神经网络算法,图像质量高但是训练时间长、渲染速度慢,不适合实时场景,广泛用于电影特效和游戏开发领域。
而3D高斯则是利用3D高斯分布的点对图像进行建模,每个高斯点包含位置、方向、颜色和透明度等信息,渲染时这些高斯分布点会被投影出来,通过光栅化技术合成,类似于在图层上泼洒高斯点,每个点贡献一个像素或片段的颜色和透明图,最终还原整个物体。
3D高斯最大的特点是建模速度非常快并且可以通过原图的RGB信息进行自监督学习。
如果用画画来比喻,NeRF就像一个画功很好的画家,根据原图中的光影和细节一笔一画的还原出来,而3D高斯则是前卫的「泼墨」艺术家,同时将不同颜色和透明度的斑点打在画布上,层层叠加形成图像。
理想的团队将3D高斯首次应在自动驾驶领域,并且在路径规划、占用格栅网络和障碍物检测等任务上都有很好的表现,MindVLA中使用3D高斯作为感知模块,和自车位置和导航信息等一同编码输入到基座大模型中。
MindGPT大模型
这次的MindVLA中,理想没有再使用开源的千问模型,而是从0开始搭建了一个LLM基座模型MindGPT。
从名字来看这似乎是和理想座舱共用的大模型,而且李想今年也公开表示成为一家AI公司的长期愿景,所以根据自身的需求搭建一个大模型是非常必要的战略方向。
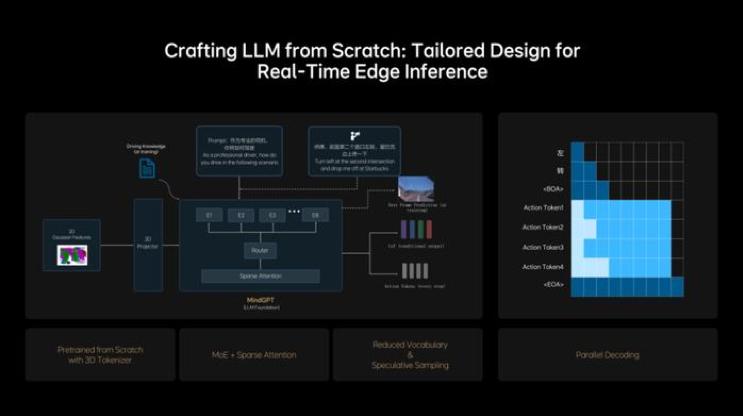
为了降低大模型在车端的计算需求,MindVLA采用了MoE混合专家架构和Sparse Attention(稀疏注意力)。
MoE模型是一种分而治之策略的神经网络架构,它将复杂的问题分解为多个子问题,每个子问题由一个独立的模型(称为专家)进行处理,与稠密模型相比,参数更少,预训练速度更快,同时由于少数专家模型被同时激活,与相同参数数量的模型相比,MoE架构可以大幅减少计算开销。
稀疏注意力机制是一种改进的注意力机制,旨在解决传统的Transformer注意力机制在高维输入或长序列数据上的计算复杂度过高的问题。通过减少注意力计算中需要处理的元素数量,稀疏注意力机制能够显著降低计算和内存开销,同时保持较高的模型性能。
理想也把当前端到端+VLM的快慢思考模式引入到MindVLA中,训练MindGPT学习这个思考模式,可以自主切换快思考和慢思考,同时MindVLA采取小词表结合投机推理,以及并行解码技术,实现了模型参数规模与实时推理性能之间的平衡。
扩散模型(Diffusion Model)
LLM大模型虽然可以直接输出控制轨迹,但是准确度不稳定,MindVLA中没有让基座大模型直接生成轨迹,而是输出Action token,然后使用了一个扩散模型解码成驾驶轨迹。
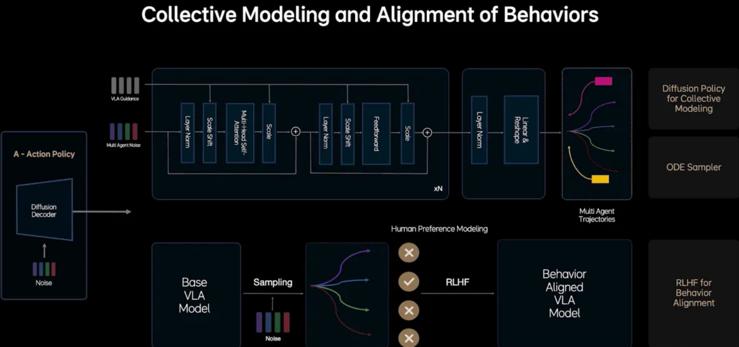
扩散模型不仅生成自车的轨迹,同时预测其它车辆和行人的轨迹,此外扩散模型还可以根据外部的条件输入改变生成的结果,通过这种特性可以根据用户的指令改变自动驾驶系统的风格。
为了解决扩散模型生成效率低的问题,MindVLA使用了基于常微分方程的ODE采样器来加速生成过程,在2~3步内就可以生成稳定的轨迹。
云端世界模型
通过高质量的数据进行训练,MindVLA大模型能够达到专业司机的驾驶水平,但是要让系统有机会超越人类,需要在云端模型场景对系统进行训练,但是传统的云端模拟都是基于游戏引擎,会出现不符合物理规律的幻觉,无法满足自动驾驶对真实性的要求。
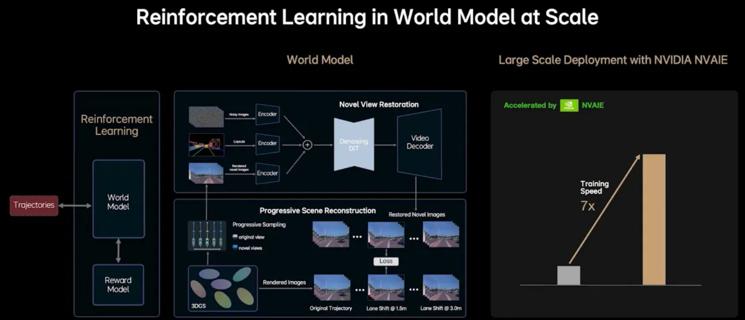
理想的做法是结合真实场景进行重建和生成,同时在不同的视角下添加噪音来训练生成模型,让模型具备多视角的生成能力,更接近真实世界的3D环境。
理想通过创新的架构和工程上的优化,让VLA率先应用在了量产车上,而且根据理想公布的计划,MindVLA不仅会应用在Thor方案上,当前OrinX的方案也会搭载MindVLA,虽然在模型的参数规模上可能有些裁剪,但是表现同样让人期待。
五、VLA,是不是唯一路径?除了理想之外,元戎也一直是VLA方案的推崇者,从去年开始元戎就在多个场合提出VLM并不是自动驾驶方案的最优解。
在前不久GTC上,元戎CEO周光也提到将用VLA打通空间智能、语言智能和行为智能,实现自动驾驶并应用在其它AI场景。
但VLA是实现自动驾驶的唯一解吗?
特斯拉并没有公开表示自己的端到端是以大语言模型为基座,但是它的表现依然惊艳。
「AI教母」李飞飞的第一个创业项目没有选择大语言模型,而是转向空间智能,通过二维图片来还原3D世界,类似的想法还有蔚来的世界模型;这些都代表了AI行业对下一代技术方向的思考,VLA是不是最优解还需要实际表现来证明。
VLA在自动驾驶领域才刚刚起步,还有很大的想象空间,今年7月份理想会开启MindVLA的推送,元戎也预计搭载其VLA模型的车型今年将投入消费者市场。
非常期待它们的表现。

美国邮政局发布全美犬咬事件排行榜

热爱100℃吉利汽车重磅推出第四代博越L,以“新一代三好SUV”之资,强势进军燃油车市场,打破传统燃油车印象,开启智能平权新时代。2025年6月14日,杭州E赛试驾场,在轻松的舞蹈开场氛围中,活动现场打造五感俱全的豪华体验场景,品牌领导、媒体老师,车主及准车主朋友汇聚一堂,感受到......
GOVY Air Cab全球首发,广汽携陆空矩阵登陆2025香港车博会

6月14日上午10时30分,西夜迷城景区内彩旗飘扬、引擎轰鸣,2025中国汽车越野拉力锦标赛叶城分站赛暨新疆4+1昆仑山汽车越野拉力赛开幕式在此隆重举行。

想打“复活赛”的哪吒,血条已经见底了

5月SUV销量TOP 10,油车疯狂反扑,宋PLUS又被抢第一

入画山河行|第四代博越L贵阳上市暨交付


长城炮全性能家族,钢铁马帮探秘茶马古道
黑芝麻智能单记章:以芯领航,决断汽车与机器人智能生态新未来

6月14日,广汽传祺携手央视新闻,深入广汽研发前沿和智能制造工厂前线,解码中国高端智造硬实力。央视主持人与广汽传祺、华为乾崑、宁德时代的技术人员,以及M8乾崑首批车主代表共同出席。同日,广汽传祺联合华为在广州白云国际机场首次实现了”出发层泊车代驾VPD(Valet Parking......

“聚变 2030”战略持续深化,广汽丰田跃入中国自研2.0时代

6月14日,上汽大众以“ONLY ID.”为主题,与100名ID.车主欢聚广州,“共创”第四届ID.Festival。

奇瑞风云T8,10万级混动SUV闭眼选它!实测续航2000km+7座独一份

百城聚力,星耀榕城。6 月 14 日,备受瞩目的星途星纪元福州福瑞星体验中心在福州盛大开业,这不仅是 “百城百店” 战略布局的重要落子,更标志着星途星纪元新能源汽车正式深耕福州市场,为当地消费者带来更前沿的智能出行新选择。此次开业盛典吸引了汽车行业精英、主流媒体代表以及众多星途忠......

丰田把研发大权交给中国?这波合资反攻太狠了!6月12日广汽丰田科技日重磅发布。 #广汽丰田 #丰田汽车 #铂智3X #铂智7 #新能源车 #广丰打造华为MMT小米智能体 #广汽丰田将推出增程车型 #广汽丰田科技日

探讨了内卷之痛,强调了企业要破局之道,出海与创新。文章指出,降价并不能解决内卷问题,奇瑞汽车采取了研发自有技术、扎根当地、重视用户生态、积极创新等方法,走出了一条可持续发展之路。

小米汽车官宣固态电池专利,预示新能源汽车新一轮争夺战即将开始

近日,多次处于舆论风口浪尖的哪吒汽车再传来新消息。有媒体报道称,哪吒汽车总部内部宣布,员工自6月12日起居家办公,办公室门禁已经失效,员工搬离个人物品需由行政部门向属地相关部门和物业报备。

汽车行业五月OTA共计升级495项功能,你的车升级了吗?









































 京公网安备 11010102004670号
京公网安备 11010102004670号