尽管具体的相关话题不断变化,但对Deepseek的讨论至今热度不减,不知道你家楼下小饭馆的老板,是不是也在考虑用DeepSeek来换新自家二十年没有变过的菜单?
当然,话题变迁的路径依旧清晰可见,从人工智能业内开始、从专业人士开始、从对“低成本”的惊叹开始。
丁科技网注意到,一个有意思的现象是,DeepSeek的出现虽然演绎了低成本神话,看起来是对规模定律的打破,站在AI创新背后、提供基础设施的云厂商们也都在积极拥抱他,但于此同时,全球头部云厂,对算力的投入看起来非但没有减少,反而还要继续增加。

(截图自DeepSeek | 深度求索)
从公开的信息来看,特别是作为全球“一哥”和中国“一哥”的两家:
亚马逊计划在2025年投入1000亿美元,主要用于云业务,作为主要载体的应当依旧是从2024年以来明显加码AI领域的亚马逊云科技;阿里巴巴计划在未来三年投入535亿美元,用于云和AI硬件基础设施,这据说超过过去十年的总和。
另外,从公开的信息看,微软、谷歌也计划增资。比如,微软提到的AI算力产能有限,因此在加大投资力度;谷歌也提到增加AI产品产能。
就丁科技网的理解,这背后可能有如下几点原因:
先就DeepSeek角度来看,“低成本”可能不是事实的全部。
通常被关注的信息是,DeepSeek-V3以不到OpenAIGPT-4o模型的训练成本的十分之一(大约是558万美元),实现了接近的性能。不过,同时需要注意的是,DeepSeek在V3模型技术报告中指出了一个事实,就是“558万美元不包括与架构、算法或数据相关的前期研究和消融实验的成本”。也就是说,约558万美元的金额,属于净算力成本。
如果从更长的时间线来看,DeepSeek母公司幻方量化在2019年的深度学习训练平台“萤火二号”搭载约1万张英伟达A100显卡,这在当时已经算“先进”了。
所以,一些可见的专业解读认为,DeepSeek给到行业最大的意义是算法创新提高了资源的利用率,而不是颠覆掉通过增加算力提升模型性能的现有规律,另外就是开源实现的友好性。
再从全球头部云厂角度来看,应该有三点诉求。
其一是推出更多可能更好的模型。不难发现,在DeepSeek看起来横空出世之后,同样作为模型大厂的全球头部云大厂基本都在对标,大有加快创新节奏的感觉,DeepSeek很像是在带来“鲶鱼效应”。全球头部云厂在尝试推出更多可能更好的模型,来应对之后的风险,为可能的竞争持续加码。
在丁科技网看来,这里还有三个细节原因,一是,DeepSeek模型并不算是全面领先;二是,全球头部云大厂大概率也有规模定律未失效的判断;三是,多模型应用才是客户在现实中解决问题时的常态,这代表依然有很多未被看到的机会。
DeepSeek用相对少的资源、更创新的算法以及开源的态度赢得了关注,那么如果是创新算法、开源再加上更为丰富的算力和训练参数呢?在丁科技网看来,云大厂们没理由不这么想。
其二是应对对后续AI应用可能更大爆发的支持。去年以来有算力成本下降的趋势,以阿里云为代表,在持续推动云服务降价、大模型降价,受益于此,一方面是AI应用更多出现,另一方面是AI应用的能力持续增强,随之而来的是AI应用用户增加,那么,对算力的消耗其实应该是会明显增加的。
其三是对相关服务使用的支持。从趋势来看,更多企业会将模型从应用实践推向真实生产,这就不仅涉及模型本身,还会涉及大量云服务的相关算力支持。(丁科技网原创,转载务必注明“来源:丁科技网”)

OMEN暗影精灵 11 游戏笔记本(后简称暗影精灵11)可以说是近期关注度比较高的游戏本,硬件规格主流,性能释放不低,关键是价格太香了,国补后RTX 5060版本最低也就6000多一点,RTX 5070版本国补后最低甚至低于7000元,性价比放在一线品牌中十分突出。今天我拿到了暗......
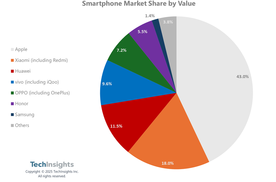
今年中国618购物节提前至5月13日鸣锣开市,各大电商平台试图通过拉长战线刺激消费。TechInsights发布的数据显示, 尽管此举带动平台总成交额(GMV)实现增长,但智能手机市场却呈现出复杂图景:销量整体持平,销售额却因零售价格普降而遭遇下滑。

下一代800 V电动汽车牵引逆变器参考设计:提高电动汽车的性能耐久性和续航里程

容声冰箱携“寻鲜之旅”养鲜答卷鲜耀南博会!
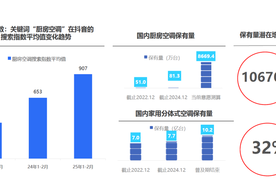
炎炎夏日,当城市在热浪中喘息,无数家庭的厨房正化身“高温孤岛”。这种困境催生了一个新兴市场:厨房空调。然而,一面是高速增长,一面是家庭渗透率仍不足1%的现实,这款被寄予厚望的产品,究竟是真正的生活刚需,还是企业炒作的精致鸡肋?

这几年中国品牌新能源车的表现可以说是又便宜又好用,消费者们也习惯了国产高品质新能源车带来的优秀用车体验,甚至经常在系统UI好不好看这种细节问题上给产品挑刺。

发动机质量日系遥遥领先,但要说技术还得是德系!

日前,多个招聘平台的招聘信息显示,潮玩巨头泡泡玛特正在招募小家电研发工程师、工业设计师等专业人才,月薪在1.5万-2.5万元,岗位职责明确指向复古小冰箱、咖啡机、早餐机的开发流程,甚至要求十年以上家电行业经验。这家以盲盒玩偶风靡全球的企业,正在向一个看似毫不相干的领域伸出触角——......

想让迷你主机更流畅?金百达DDR5 5600笔记本内存提升的不是一点点

全球高端电视市场的竞争格局,正迎来中韩巨头深度较量的关键时期。一边是以三星、LG为代表的韩国巨头,凭借深厚的显示技术底蕴和品牌积淀强势布局;另一边则是以TCL、海信为首的中国军团,以极具性价比的创新技术与灵活策略发起冲击。这场交锋的核心焦点,已鲜明地聚焦于新型显示技术路线的争夺:......

当城市的霓虹渐次亮起,结束一天忙碌的人们总会期待一场舒适的沐浴 —— 它不仅是身体的清洁仪式,更承载着卸下疲惫、焕活身心的期待。然而,传统热水器长期困于 “恒温”“节能” 的功能内卷,让沐浴体验停留在 “有热水用” 的基础层面。

好开 够稳 更聪明 | iCAR V23以全能实力燃爆昆仑决世界格斗冠军赛104

东风日产这把AI椅子绝了!坐上去秒扫描全身,0.3秒腰托顶上来,按摩像八个师傅伺候!百万豪车技术塞进办公椅,还能自己OTA升级学习?躺赚了属于是!

在生物柴油上涨的推动下,相关上市公司业绩表现随之修复。

罗姆宣布,与领先的车规芯片企业芯驰科技面向智能座舱联合开发出参考设计“REF68003”。

“一家在海外市场已经很有知名度的中国电视品牌,利用其现有渠道转做空调,但其净利润率仅为3%。”2025年6月底,深圳“中国企业出海高峰论坛”上,格力电器市场总监朱磊的发言引发关注。

智能驾驶当下的发展方向,一个是从L2级别辅助驾驶向L3级别自动驾驶迈进,另一个就是实现算力硬件的自研,比如说小鹏即将在G7上首发上车的自研图灵AI芯片。哪怕是财务状况一直紧张的蔚来,也在不遗余力推动自研神玑NX9031芯片的发展。

强到没朋友,指纹加密+100W快充,这款至高8T硬盘盒颠覆我的体验

全新荣耀一步不退!“V587”AI全家桶以自研技术重构终端生态

中国车企自动驾驶正经历量产普及、技术跨越、生态输出的三阶跃迁,2025年也将是针对L3级自动驾驶量产的爆发元年,中国车企需把握数据主权与技术普惠双轮驱动,构建全球智能汽车新秩序。我们在家“坐等”新车上门的时代,也许就在不远的未来。





























 京公网安备 11010102004670号
京公网安备 11010102004670号