
编者注:
这篇文章内容原本是用于驾仕派内部的年会报告,没有想到2025年的春节直接被DeepSeek刷屏了,尤其是写内容的时候还是Deepseek V3,结果开完会就推出了DeepSeek-R1-Zero、DeepSeek-R1两款模型,对整个AI行业影响很大。进入了3月,AI发展更是有一日千里的感觉,从全民智驾到12万买激光雷达,从端到端到VLA,汽车也快速被AI改变。为此,驾仕派重新整理了内部对AI发展的历程、基本信息,以及对AI对汽车行业未来发展的影响,希望汽车媒体能够重视AI的重要性,也算是一次“开源”。
2025年的技术发展主线,毫无疑问会是AI人工智能。
其实不管是汽车还是经济发展,都已经是一个明盘,我们只需要静静地等待结果就行。以汽车行业来说,从品牌到技术发展都是一个收敛的过程,也就是一个你有、我有的过程。各个品牌的排序大致已经定下了,接下来主要是一些细节的调整。技术层面,目前电动车从产品本身来说也没有什么特别独特的地方了,三电系统、安全、甚至智驾都会因为AI时代的到来而同质化。
2024年是科技界狂欢的一年,蜂拥而入的AI公司激发了对科技创新的激情。这有点类似于2010年手机行业的情况,iPhone 4发布之后带动了整个中国科技公司开始做手机。而本质上推动这个手机产业的不是手机本身,而是移动互联网的需求。
现在科技行业也一样,有了OpenAI这家公司打造的ChatGPT,有太多的AI公司出现,也推动了中国AI行业的爆发,涌现出大量的新兴机会。人工智能开始更深切地改变普通人的生活,也开始影响到汽车、媒体不同领域。
为了更简单、更快速理解AI对汽车行业的影响,我们重新梳理了AI的知识架构和对其的理解,希望能够很精简的给大家聊聊AI是什么,AI会带给汽车什么,以及AI将如何改变驾仕派。
【PART 1:AI是什么】
1、AI的故事
AI就是Artificial Intelligence,即“人工智能”。可能是二十年前我们会觉得AI很远,记得2001年有一部斯皮尔伯格拍的科幻电影《人工智能》,讲的就是一个机器人拥有情感然后寻找父母的故事。当时我们对AI的理解大概就有了一个雏形:人形机器人、通用人工智能的程序,再加上情感的理解。
到了2025年,尽管距离这三点还有一定距离,但是我们可以感知到或许已经非常接近了,AI不再是科幻电影里面的场景。

人形机器人,现在有个更热门的词语叫做“具身智能”。而特斯拉也一直在打造人形机器人,这被视作一个巨大的机会。
更广泛的认知是,机器人不仅仅是人的形态,汽车也是机器人的一种,叫做自动驾驶车辆。
而通用人工智能(AGI,Artificial General Intelligence),就是指可以自主感知、决策、执行,甚至学习的人工智能。业界认为目前距离AGI还有一段时间,但是可能我们已经拿到了那把很关键的钥匙,叫做“生成式人工智能大模型”。
2022年11月30日,Open AI的CEO山姆·奥尔特曼(Sam Altman)发布了一条推特,宣布ChatGPT上线。
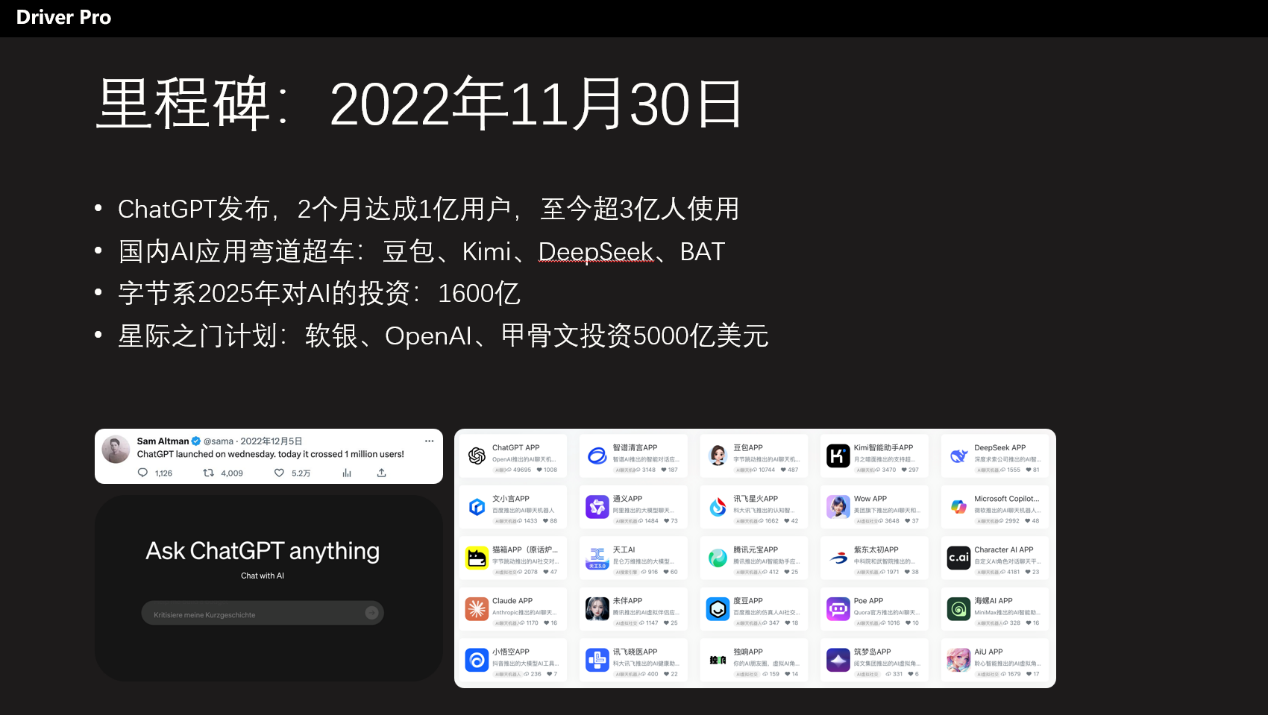
只用了不到两个月时间,这个和聊天软件类似的AI应用的用户超过了1亿人,成为互联网有史以来用户增长最快的APP,到现在ChateGPT大概有3亿人使用过。这并不包括国内,因为国内主要用的豆包、文小言、Kimi、讯飞星火等等,前三个月活是千万量级。
有意思的是,打破ChatGPT的不是别人,而是中国人自主研发的大模型DeepSeek,其在2025年1月实现了1.25亿用户,而80%来自于1月最后一周——换句话说,DeepSeek只用了一周实现了1亿用户。这还是在DeepSeek没有做任何广告情况下达成的。
这或许也可以看出,AI在2025年的号召力。
2、Transformer到底是什么
可能很多人会好奇的是,ChatGPT到底是什么?如果你们使用过Kimi或者豆包就会发现这个体验非常神奇,你给出一句话,就能自动生成一系列的内容,这和曾经大家熟悉的搜索引擎完全不一样。
首先我们要知道,什么是GPT。这三个字母其实是Generative Pre-trained Transformer,直译为“生成式预训练转换器”,这里面最核心的单词其实是“Transformer”。
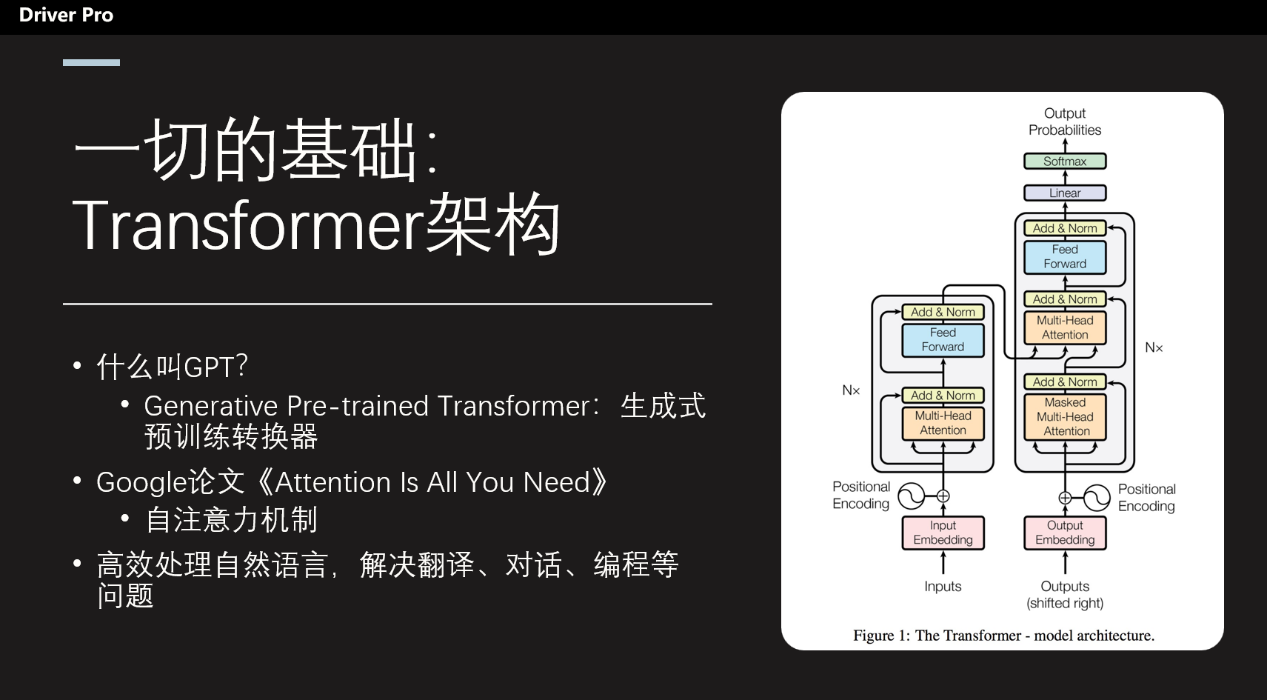
Transformer架构非常、非常、非常重要,几乎是目前所有生成式人工智能领域大模型的基础。
这个Transformer本质上是一种神经网络架构,就是可以通过自注意力机制捕捉全局信息。
它是由Google的人工智能团队提出来的,当时Google的团队写了一篇论文叫做《Attention Is All You Need》,里面提到了一个“自注意力机制”( Self-Attention)的内部构件,可以十分准确高效地对自然语言领域的问题进行处理,以完美地解决翻译、对话、论文协作甚至编程等复杂的问题。
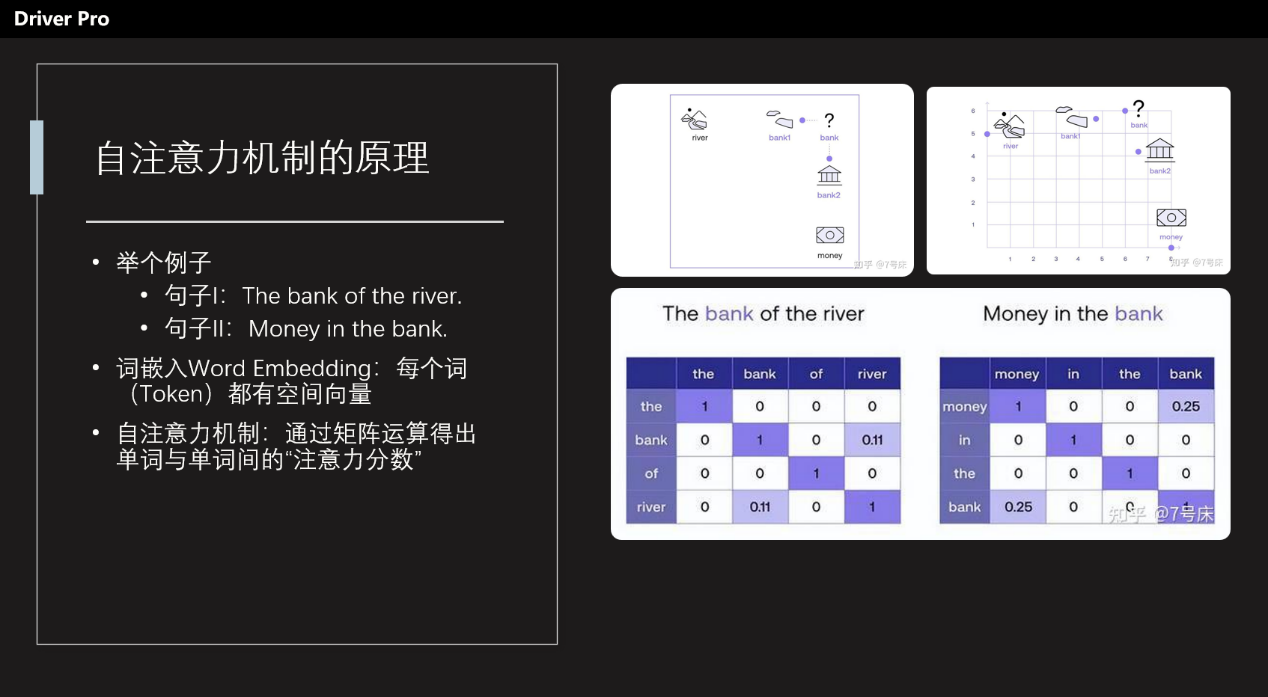
这个自注意力机制非常重要,解释起来其实比较复杂。简单来说就是根据一组矩阵运算,计算一个长句里面某个Token(简化理解为单词)与其他Token之间的加权计算结果,也就是两个Token之间概率关系。两个Token之间的概率越高,就说明越相关,从而输出一个概率数列,然后再去比对和其他Token的概率,从而输出长文。
值得一提的是,Transformer架构有一个前提动作,叫做词嵌入Word Embedding。就是给每个词都设计了一个空间向量值,表示这个词的位置和方向。这个位置不是三维的,可能是5000维的,但是向量就可以用矩阵计算,这个就可以交给GPU处理了。这也是为什么英伟达的算力卡卖得那么好,因为GPU非常适合做并行矩阵运算。
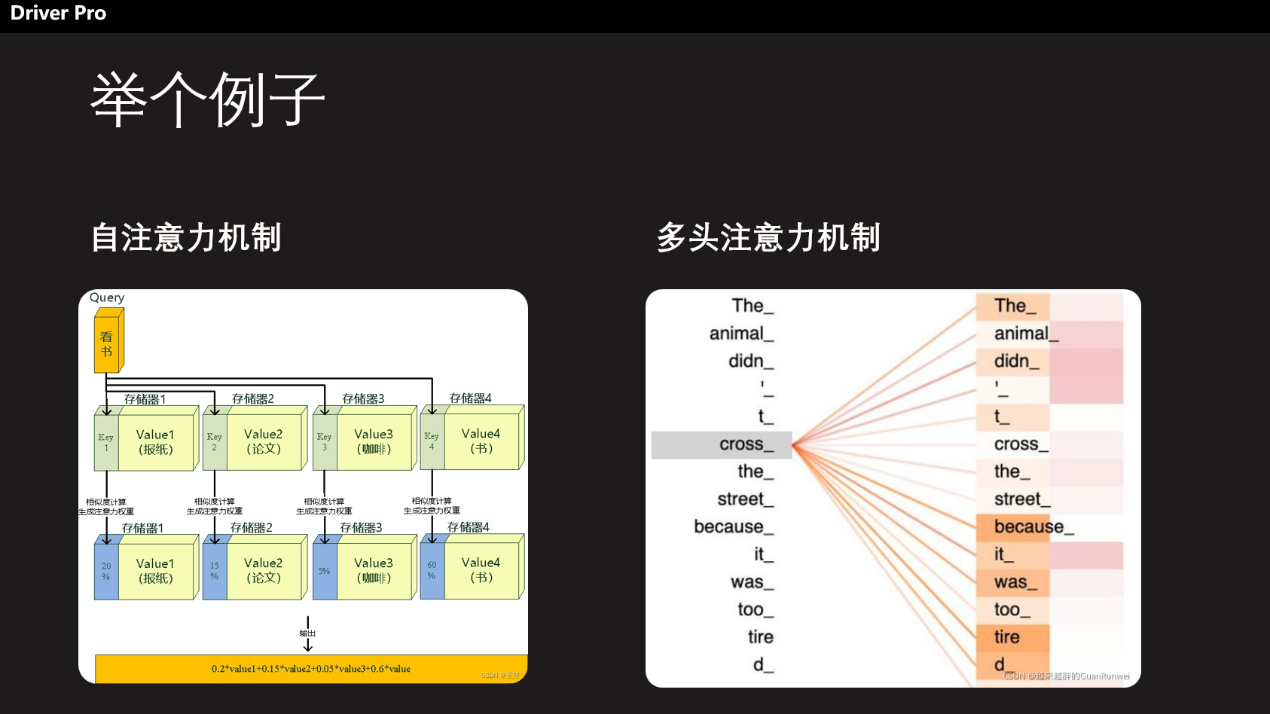
但自注意力机制只是一个基础,之后要解决上下文问题还需要多头注意力机制。但是原理是一样的,只是将查询、键和值通过不同的线性变换映射到多个子空间,然后在每个子空间中分别进行自注意力计算。而DeepSeek创新地使用了“多头潜在注意力机制MLA”,通过低秩联合压缩技术,减少了推理时的键值(KV)缓存,从而在保持性能的同时显著降低了内存占用,进一步降低了成本。
基本而言,Transformer架构就是猜词。一个词一个词的猜下去,然后输出连续的结果。GPT本身就是逐词生成、并结合上下文推测。

这就是Transformer最基本的原理。至于说为什么Transformer神经网络架构可以得到这样的结果,也没有办法深究,因为神经网络本身就是一堆数学函数,然后AI科学家用一种数学方式去计算里面的矩阵而得到一堆的数字,然后再编译为人类的语言。
这也就是人工智能的神奇之处,我们对过程其实是不可控的,但是能够得到一个大概率正确的结果。
实际上,Transformer架构最早是用来解决翻译问题的,因为可以通过词嵌入和自注意力机制实现高精确新的翻译。所以在某个时间点,驾仕派有一段时间做海外内容翻译的时候,我个人是觉得Google的翻译真的是很神奇,完全可以正确理解文章,不再是只能粗看。而现在大家直接把文章丢到大模型里面会发现,翻译速度和质量都相当高。
对于机器来说,它没有所谓的语言障碍,它对单词的记忆都是词嵌入系统,所有的单词都是向量形式的,所以无论输出中文还是英文,对它来说没有区别。这也是AI带给现代人的一个极大的改变,以前英语好的人才能直接学到全球的知识,普通人只能看转译的内容,而现在AI大模型几乎直接填平了这种语言的鸿沟,也是创新能力快速增长的原因。
3、什么是大模型
那么GPT提到的预训练又是什么意思呢?
实际上我们去理解了Transformer架构之后,就要去做大量的神经网络层来完成一个大模型搭建。其实每一个神经网络都是一个函数,要写足够多的函数来确保这种预测能够正确的做下去。

有函数就会有参数,也就是可训练的变量,这些参数就相当于调节旋钮,来确保你这个大模型能够有一个很高的预测单词的概率。而这些参数怎么得到呢?就是通过一种叫做强化学习的机器学习的方式。
比如我们把一堆资料输入进去,让机器来也来生成一堆结果。这些结果中有对的、也有不对的,机器自动比照结果,给对的加分,给不对的扣分,最终去确定哪些参数是可以确保生成正确结果的,然后自动进行优化。当然,工程师也可以进行微调、进行强化学习两个步骤,专门针对一些特定的参数进行优化,我的理解是写一写规则。
当然,最近的DeepSeek做了一个更先进的技术路径,就是R1-Zero纯强化学习(RL)。Deepseek提出了一种新的强化学习算法——组相对策略优化(GRPO)——就是让大模型先给出思考过程,然后再给出最终答案,通过组内样本的相对奖励比较来优化策略模型,而非依赖传统的价值模型(Critic Model)或跨组比较。
这就与当年AlphaGO Zero的技术思路非常相近,相当于不再去学习棋谱,而是直接自己和自己下棋,再去判断下得好不好,而未来的L4自动驾驶也会走强化学习的路线。

总之,大模型之所以叫大模型,就是因为参数规模量大,比如GPT-3差不多是1750亿参数,马斯克旗下公司xAI开发的Grok 3最大3140亿参数,DeepSeek LLM大概是6700亿参数。参数越大,一般模型能力就越强,但也不是越大越好,因为有成本的要求,训练大模型花费很高,所以一般会有一个限制。
同时越大的模型,运行全量的成本也很高,这时候又要提到DeepSeek了,它使用了MOE混合专家模型,即便是670B的大模型,但是对特定问题只需要调用一部分参数,这样就降低了运行成本。
目前大模型的应用其实非常多,但是Transformer架构主要是应用在大语言模型,则被称为LLM——Large Language Model。现在也有很多AI公司使用Transformer用于图像技术,比如去进行图像分类、目标检测等等。
而和汽车行业最息息相关的就是自动驾驶里面Transformer可以处理多摄像头的图像数据,被称为ViT,Vision Transformer。
Transformer也不仅仅是做NPL自然语言处理,它本质上是一个自注意力机制、也就是一切符合上下文逻辑的系统理论上都可以用Transformer架构。所以在Transformer很快就被应用到了自动驾驶领域,特斯拉开始用的是BEV+Transformer系统,这里面的Transformer系统主要就是把图像空间转变为向量空间。
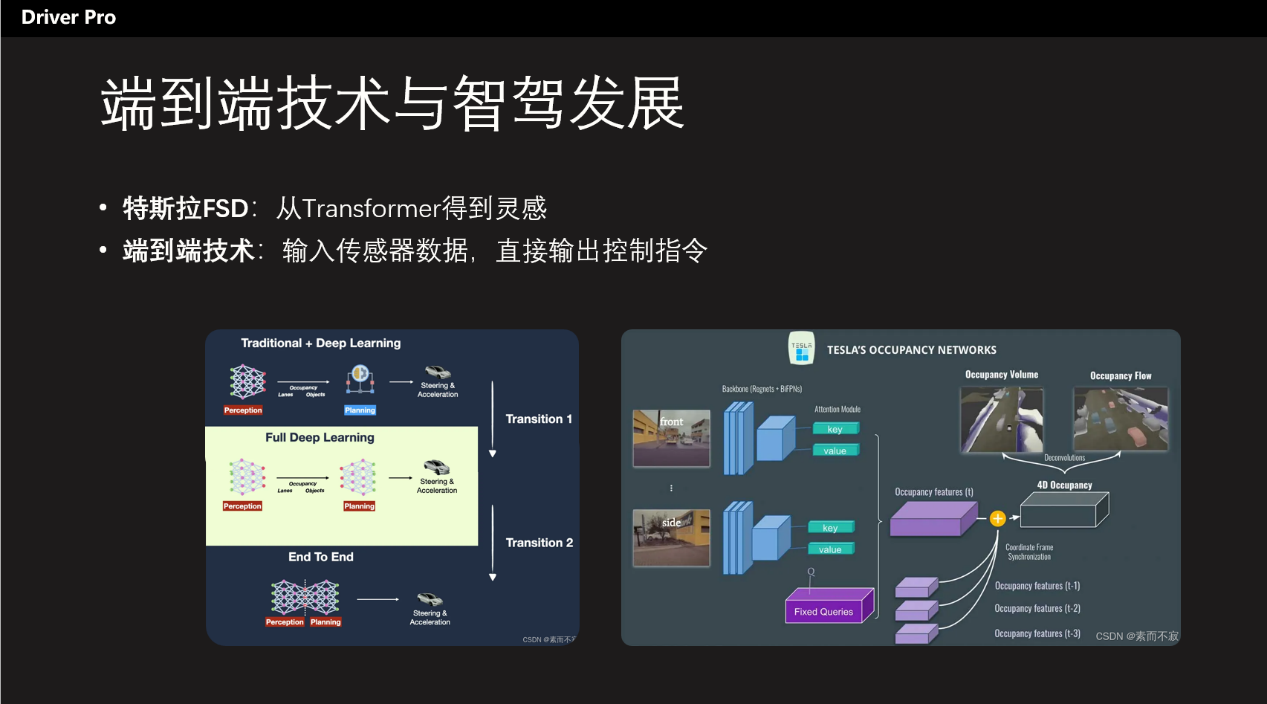
虽然我也不知道是什么意思,大概可以理解为特斯拉用Transformer专门构建了一个数字化的空间,也把摄像头拍到的物体再转化到数字化空间里面,这样就确定了车辆和周围环境的关系、距离。所以Transformer被ChatGPT应用之后,马斯克很快就决定要全面转向端到端技术,因为背后的原理其实都差不多。
另外还有大模型就是VLM,Vision Language Model,视觉语言模型。简单来说就是把看到的画面翻译成语言,然后再来判断怎么做,相当于看图说话。
当然,Transformer不是终极答案,而且Transformer的短板也很明显,比如对长文的理解是有限的,注意力机制没有办法扩展过长,那样太过复杂。具体原因是Transformer架构是一个二次方复杂问题,内存需求是以平方翻倍的。因此,现在也有很多新的模型架构出现。
现在大概有其他几条发展路线:
1、线性注意力(Linear Attention)路线,把二次方复杂度转变为线性,降低了难度;
2、第二条路线是状态空间模型(State Space Model,一种通过状态转移来建模序列关系的方法);
3、基于在线学习(Online Learning,模型在接收新数据时实时更新的学习方式)的递归更新机制;
4、TTT(Test-Time Training)引入了更复杂的非线性变换等等。

这些新技术里面有很多中国公司在参与。比如状态空间模型中,中国公司地平线就提出了Vision Mamba技术,被定义为下一代通用视觉主干网络。同样在线性注意力路线上,中国AI公司Minimax发布了开源模型MiniMax-01,首次大规模实现了线性注意力机制,每8层中有7层采用了基于Lightning Attention的线性注意力,仅有一层保留了传统的SoftMax注意力。
现在AI大模型更像是当年的“百团大战”时代,格局还没有完全稳定下来,体验和应用上也没有拉开差距,但是我们完全能够看到自己的生活已经被改变了。
大模型之所以有这么强的智能体验,很大程度上是源于Scaling Law,规模法则。训练越大的模型,用越多的数据喂给模型,模型越可能涌现出“接近人类的智慧”。而且人类完全不知道为什么AI大模型可以涌现出智能,因为在大规模的神经网络连接中,某一层出现了新的认知能力,这是完全没有办法预测和控制的。甚至于很多AI科学家一直担心AI会出现超越人类的智慧能力,需要对AI的发展进行限制。
目前业内也有一个观点认为,Scaling Law已经失效了,原因在于人类的现有知识库已经没有办法让大模型继续成长,大量的信息已经是没有意义的。不过英伟达已经说了,可能预训练的Scaling Law不行,但是还有训练后的规模定律和合成数据生成,依然可以保持人工智能增长。
此外,现在也有更多的公司开始转向推理模型,解决一些高难度的科学问题,包括写代码这些,进一步提升了人工智能的使用范围。
特别是DeepSeek找到了一种可以压缩算力、节约成本的技术路径,还是一个开源的策略——之前的推理模型主要是OpenAI在推,但OpenAI是闭源的,外界不知道他们怎么做到的,而DeepSeek可以说是第二家复现了大模型推理能力的企业——几乎让所有中国AI企业都找到了新的前进动力。
【PART 2:AI给我们带来什么】
1、智能座舱不止于语音
AI给我们带来的改变肯定很多,包括驾仕派发布的使命、愿景,都有AI的帮忙,做了很多的提示和参考。
对于我们汽车媒体的工作来说,AI改变最大的地方就是我们和汽车的交互上,这种交互既包括智能座舱的体验升级,也包括智能驾驶为我们带来的体验改变。
今天我们要聊的汽车智能的一些简单AI技术。
首先是智能座舱上,理想汽车说自己有Mind-GPT,蔚来说有自己的Nomi GPT,凯迪拉克傲歌用的是百度的文小言,很多车企的合作伙伴是科大讯飞的大模型。之前车企要在座舱上大模型其实还是一个比较高成本的事情,因为要么是从开源模型上自己稍微训练一下、部署在自己的云端服务器,要么就是接入现有的国产大模型,后者按照Token收费也不便宜,用户感知也不强。

现在,随着DeepSeek开源了V3和R1之后,车企们又纷纷说把DeepSeek“深度融入”到了座舱,大模型上车已经成了“毫无成本”的事情。因为DeepSeek的API接入非常便宜,效果也好,完全可以满足用户偶尔的需求。
可是大家都用DeepSeek,就等于大家都不用,智能座舱之间拉不开差距。实际上,这些大模型上车后很重要的一点就是把上面我们提到的LLM大模型能力加到了车辆交互上,要把LLM和现有车端语音识别的反馈做联动。
举个例子,很多时候大家测试时会发现这些AI大模型上车好像没有太多意义。这是因为很多产品没有做大模型指令调用车内APP的功能,就好像你说这是一首什么歌,大模型给了你答案,但是你想听就必须重新说一遍,让车辆语音系统识别你的需求。如果GPT功能和车机功能打通,那体验就会好很多,这已经有很多车企开始做了。
只是背后的工作量也不小,一是DeepSeek目前没有实时语音接口,所以需要车企自己做;二是语言大模型的指令和车机指令可能发生缠绕,梳理两者的输入需求也是一项车企需要自己做的事情。
语音交互方面还有一个地方在于大模型今后会放到端侧运行。什么叫端侧大模型?就是本地化运行,不需要借助网络也可以迅速完成识别任务。现在很多时候使用车内语音交互会发现,给出了指令、然后识别有个过程,原因就是这个识别可能是放到云端的,来回时间可能是3秒左右,虽然准确率很高,但是会让人觉得卡顿、慢。现在做得好的新势力大概能做到几百毫秒,但是需要依赖5G网络。
而如果车端有一个大模型能够直接运行,那可能响应时间可以缩短到几十毫秒,而且不怕没有网络。目前OpenAI的一个目标就是蒸馏出更小参数量的基础模型,包括可以让手机运行的端侧模型,这样就可以大大提升智能座舱的交互能力。
当然,除了在车端做更小参数量的LLM模型之外,现在很多AI初创公司、也有大公司在做语音生成大模型。
现在的方向主要有几个,一个是从传统的TTS流程(文本→音素标注→时长模型→声学特征 →波形合成),变为端到端流程(文本→直接生成语音波形),这样保真度与一致性更高,可以支持长文本的连贯生成。
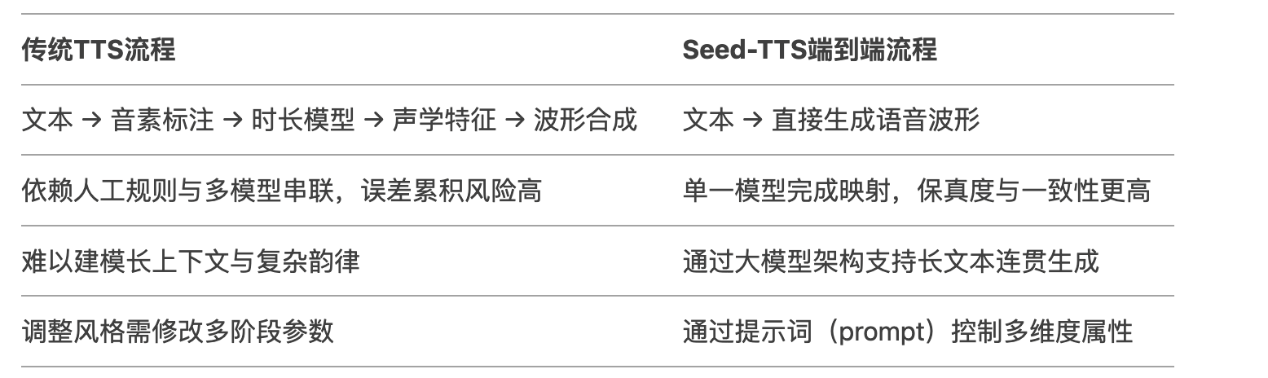
目前豆包的AI团队已经做出了Seed-TTS基座模型,可以实现文本到语音的端到端流程,这样对指令的理解和长文本的输出就有更好、更快地输出效率。而马斯克最新的xAI在发布Grok-3的时候就预告了,他们会发布一个语音交互功能的大模型,也是类似的能力。
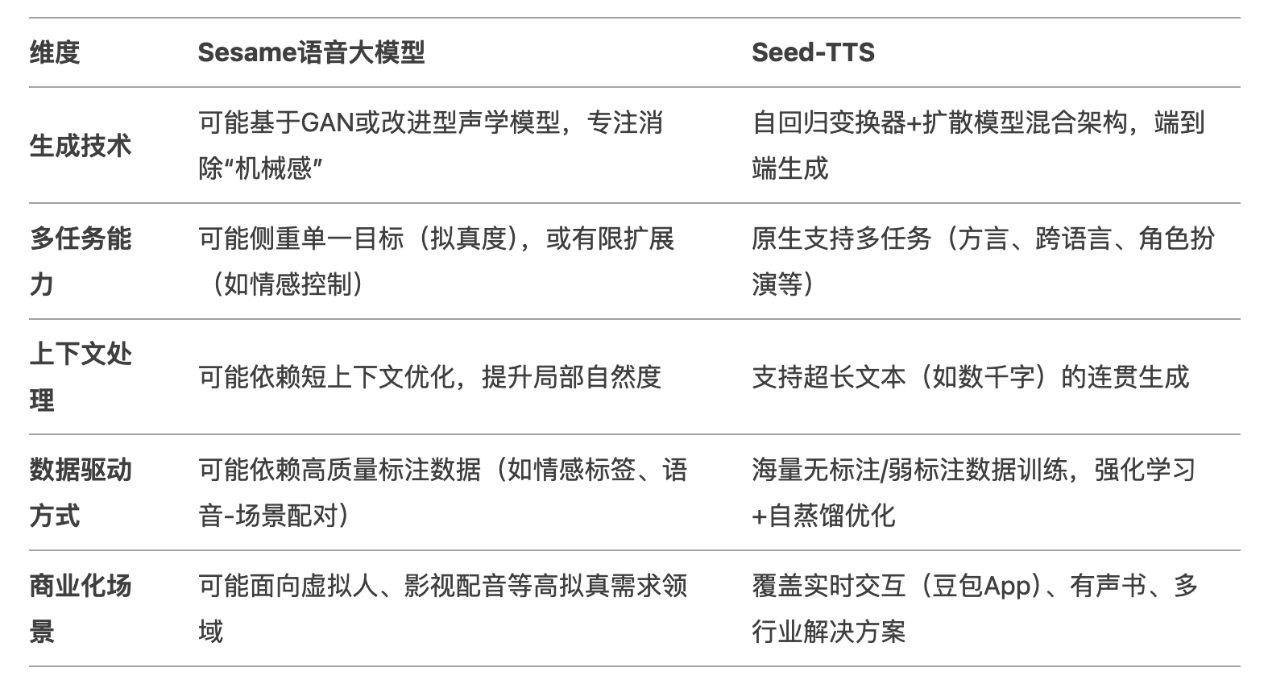
第二个做控制语音情感,去掉计算机生成语音的机械感。传统的TTS(文本转语音)模型是直接从文本生成语音输出,但缺乏自然对话所需的上下文感知,所以听起来就总有一种机械感。但是我所体验的一家SesameLab的创业公司做出来的语音模型就非常逼真,因为他们研究出对话语音模型(Conversational Speech Model )使用transformer的端到端多模态学习任务,它利用对话的历史记录来生成更自然、更连贯的语音。
第三个则是更长远的语音输出语音的端到端大模型,不用在转换为文本。百度就表示他们想做端侧语音2B-20B左右,但目前还没做出来,因为声学大模型相比语言文字大模型更复杂。而OpenAI GPT-4o据说是首个真正实现端到端语音输入与输出的通用大模型,唯一的问题是太贵了。
技术在发展迭代,智能座舱的前景肯定必须是多模态大模型,就是融合视觉、文字、声音等等,能够直接语音输入输出、可以捕捉摄像头看到的信息输出内容。
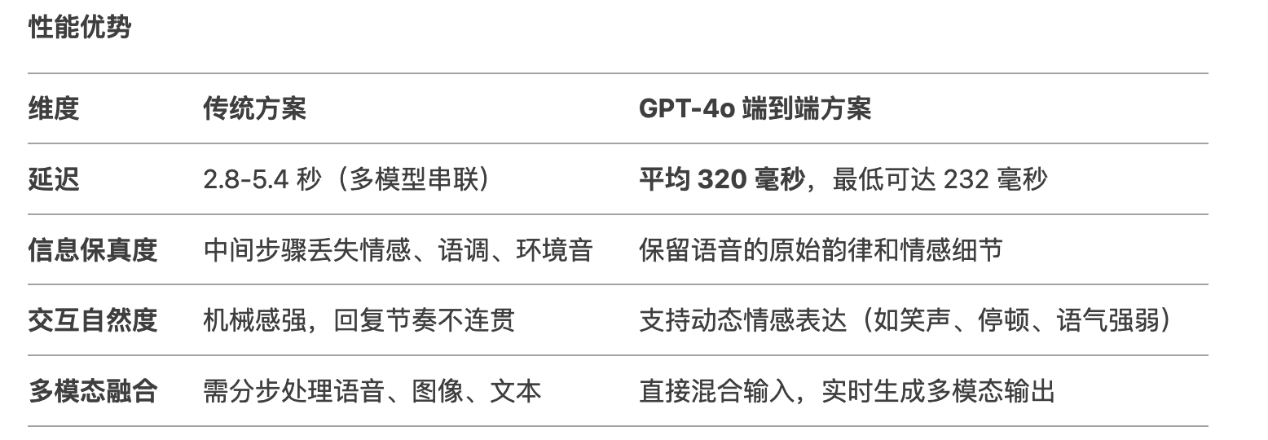
这个我们在小米SU7上就有过一些体验,比如拍一辆车可以问小米SU7是什么车,只是这种处理还是上传到云端,用云端大模型去解决,没有时效性的需求。真正有时效性的可能是发现驾驶员出现事故或身体状况异常后,可以协助报警、控制车辆等等;又或者车内摄像头可以捕捉驾驶员的唇语动作提升语音识别准确性,这些也和隐私的要求高端相关。
智能座舱未来的一个方向,大概率会是车端一个小模型再配合云端大模型去解决,类似苹果AI目前的一个分布式解决方案,把隐私留在车端。不过和目前语言大模型相比,智能座舱的大模型必然需要是一个原生多模态大模型,这样使用的效率和范围都会更高。
2、智能驾驶不止于端到端无图
关于AI,更多可以聊的还是智能驾驶。
端到端是2024年中国智能汽车行业最炙手可热的词语,那什么是端到端智能驾驶呢?
这个端到端不是说从一个车位到另一个车位,而是End to End的意思,其实是一种系统设计理念。之前说到了Transformer对特斯拉的启发,其实端到端技术本身也不是一个仅仅用于汽车行业的术语,LLM本身就是一个端到端模型、目前智能座舱追求的语音输入直接输出也是端到端模型。
只是汽车方面更强调端到端智驾这个通用术语,大致意思就是,车辆从摄像头、激光雷达这些传感器输入路面信息,经过一个智驾算法,然后就可以直接输出车辆的执行控制。
端到端技术对应的是早期的规则智驾。规则智驾就是我写好一堆规则,看到红灯要停、前面有车要停、左边来车了要避让等等,但是实际交通行驶场景太复杂了,每个城市也有区别,传感器看到的信息也有可能有损耗,所以规则是写不完的、总有Corner case。
端到端怎么实现的大家不用去详细了解,只需要知道它的目标是从传感器输出原始数据,再去执行就可以。但是这种完全输入-输出的策略叫做一段式,One Model端到端,比如特斯拉、理想这些就属于一段式。
同时,汽车行业也有两段式端到端,比如华为ADS 3.0就是两段式,一部分叫做GOD(通用障碍物识别)大网,负责感知;另一部分叫做PDP(预测决策规控)网络,相当于把感知和决策分开了,而且还有一个兜底的本能安全网络。小鹏也是类似的,不过更复杂一些,大概是三部分。而连接不同大网的一般也是神经元,而不是直接简单的输出、输出的关系。

这两种模式没有说谁一定更好,因为一段式效率高、训练起来也更快,但问题在于如果你发现一个场景出问题也没办法很快修复,因为你不知道是哪一个神经网络层可能出了问题,只有去慢慢调参数或者去强化学习。两段式的好处就在于你可以找到一定的问题原因,是感知网错了,还是决策规控网错了,方便修改,安全性也更高。而且两段式之间也不是完全看到的一条线连接,小鹏就说他们还是用的神经网络链接。
那么理想汽车可能还有一点区别,就是做了一个VLM大模型,用视觉图片翻译为语言,然后可以解决一类类似的问题,比如公交车道限行、雪天的路况识别等等。这是理想做的一个兜底。

▲图片来源:元戎启行

而端到端的下一步是VLA模型,也就是视觉-语言-动作大模型。这个全新的模型就可以理解为是一个多模态大模型,可以直接从视觉传感器中看到内容,理解画面中的文字,也能够理解画面中可能交警的手势、带指向性的红绿灯等等。因为VLA整合了语言大模型的能力,也就有了思维链,这样就可以更好地理解人类的行为。
或许我们可以把VLA理解为是融合现有的视觉端到端,再加上理想的VLM,还有DeepSeek-R1思维链能力的多模态大模型。那突破的关键点就在于车辆上的算力,以及对云端模型的蒸馏了。
总之,通过结合视觉和语言处理,VLA模型可以解释复杂的指令并在物理世界中执行动作。因此,VLA也被视作一种通用型的端到端大模型,也不仅是运行于数字网络上的Digital AI,而是可以用机器人和这个世界交互,也就是现在流行的说法:Phycial AI具身智能。
目前机器人产业的创业公司们则是更激进,而最积极发展VLA的车企是理想汽车。按照VLA的理念,在使用了VLA以后控制汽车或者机器人并没有什么本质区别。
最近智元机器人这家公司就发布了相关的论文,推出了ViLLA架构,也就是Vision-Language-Latent-Action,核心原理是通过结合多模态大模型VLM与混合专家MoE系统,从而实现感知到动作执行的端到端协同优化。
而在汽车领域,最接近VLA的应该是Waymo的EMMA(端到端多模态自动驾驶模型),然后国内AI企业元戎启行在去年9月宣布了他们正在开发基于英伟达Thor芯片的VLA。而理想汽车据说也准备封闭式开发VLA,准备在七月的时候和纯电动车i8一起推向市场。
一旦VLA大模型跑通,那么智驾就将分为“端到端时代”和“VLA时代”,先发优势又会进一步拉大,而今年才刚刚开始投端到端智驾的车企又变成了落后者。

3、自动驾驶的分叉路
蔚来这边做了一个叫做NWM的大模型,叫做世界模型。世界模型相当于去模拟真实世界,是关于做和看的,而现在的LLM是基于语言的,是“说”。所以世界模型本质是基于像素或者体素(立方体像素),而LLM是基于词嵌入,也就是单词。
所以蔚来做的NWM还是很领先的,但是和端到端智驾的关系也没有那么直接。这里面涉及到智驾的未来,会有两个方向:一个是无限接近L3的L2.999999,一个是L4。
两种路线看似好像需求都是一样的,但本质却完全不同。按照目前端到端的技术发展,逻辑上还是模仿人的驾驶,既然是模仿,就不可能超越人。而且人对智驾其实会有比较奇怪的认知,第一是要求智驾不能犯错,但是人类自己都做不到;第二是当智驾真的做到500公里接管一次的时候,人类真的能在那一次要接管的时候做到接管吗?那显然也是不可能的。
所以做L4不会用现在端到端预训练的方式,而是会用到刚刚提到的蔚来的世界模型。世界模型本质上是L4做准备的,因为车辆可以在世界模型里面生成场景、并且寻求最优解。这有点像《复仇者联盟3》里面奇异博士的那种能力,能够看到几千种结果然后选择最好的执行。但是我个人理解世界模型主要是一个大模型的训练场,训练好了拿出来给车辆使用。而且L4车辆的传感器就不会只是一个激光雷达、几个摄像头,而是会要求更多的激光雷达、更多的摄像头,确保十万公里级别的安全。

因此,端到端去做L2.9,是和做L4完全不同的。全球智能驾驶第一梯队的企业公认是两家,一个是特斯拉做的L2.9,另一个是Waymo是做的L4;在国内大家注意不多的是,小马智行和百度都是做L4的。
至于世界模型能不能训练出L2.9的端到端智驾?我个人的观点是肯定能,但是这样相当于先跳出三界外、再到五行中,蔚来可能就是这个逻辑。只是做出世界模型的难度肯定远远高于直接在真实世界里面去采集数据,毕竟世界模型要去做的是那些万分之一概率的Corner Case,如果只是L2.9完全没有必要。
4、决定智驾的三件武器
讲了端到端技术的基础,再聊聊是什么决定车企在端到端技术的领先能力。
普遍来说有三个:数据、算法和算力。用一个汽车领域的比喻,数据等于燃料,算法等于驾驶技术,算力等于马力。
为什么理想能够只用八个月时间追上华为、小鹏?因为理想选择了正确了算法,那就是端到端技术,然后也有大量的驾驶数据,一百万辆在路上跑,最后理想还有钱,买到了大量的算力卡,所以理想就成功了。
当然,数据其实要求没有想象那么高,大家基本上有一个满足Scaling Law规模的数据就够了,我个人猜测是400-500万Clips高质量数据就够了。算法大家可能都差不多,找一个算法团队来做,有明确的方向就能够做出60分的产品。所以长城汽车的智驾好像一下也起来了,极氪好像也搞出来了,因为这些都是行业的共同知识。
剩下的就是算力,有算力才能做大模型的迭代,华为和理想的算力大概都是8EFLOPS,理想汽车可能更高一些。其他几家就不说了,都是很少的,而特斯拉有多少:100EFLOPS。
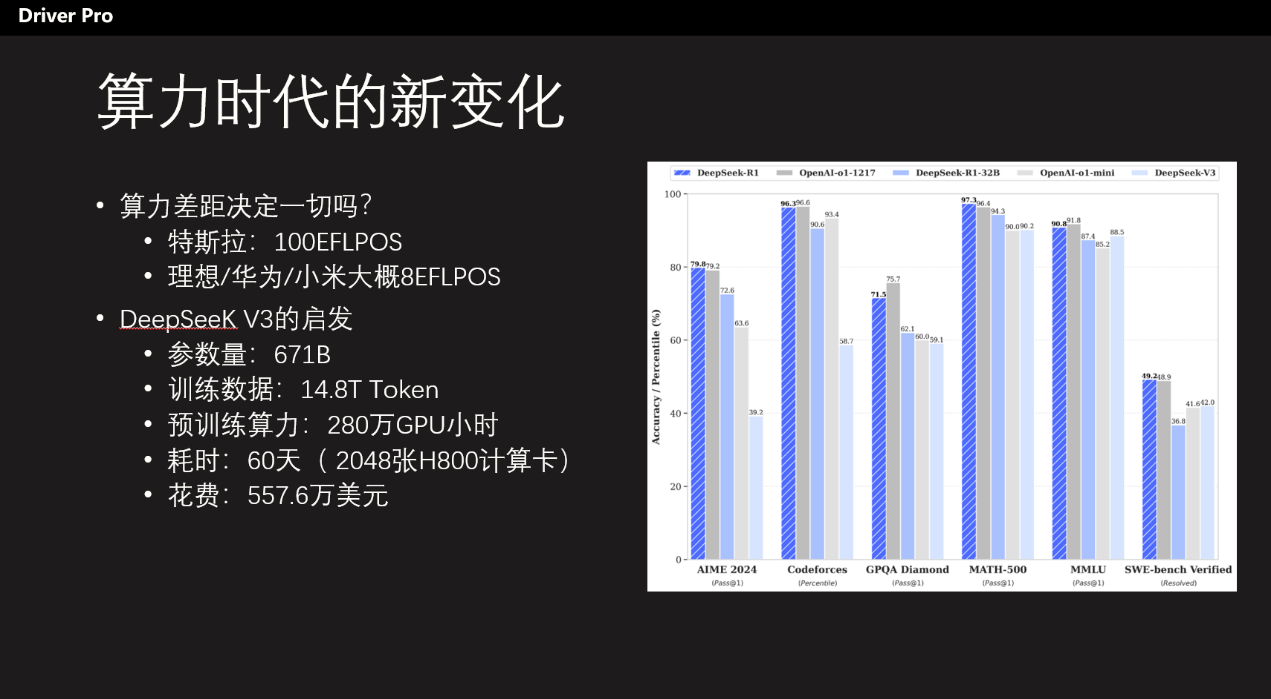
当然,算力不是终极答案。AI业内人士做了一个比喻,如果说AI要提升1000倍的效率,那么算法可以做到100倍的提升,而算力能做到10倍的提升。现在的问题是算法看上去还没有找到新的演进方向,那么就只能去拼10倍的算力。
可是万一100倍效率算法出现了呢?
比如DeepSeek V3这个模型就是典型用算法打败算力的例子,直接把海外AI圈震惊了。因为这个参数量高达671B的大模型,在预训练阶段仅使用2048块GPU训练了2个月,且只花费557.6万美元,其训练费用大概是业内主流大模型的十分之一。而且DeepSeek V3的性能表现非常出色,甚至而后有发展出了DeepSeek R1模型,直接能够和OpenAI最新的GPT-4o扳手腕。
DeepSeek的出现似乎给中国AI科技领域解决了一个很大的难题,那就是不再惧怕算力卡禁售的问题。华为、理想和特斯拉可能差10倍的算力,可是只要能够优化训练策略和数据策略,可能大模型训练的成本可以大幅下降,那么车企就会把更多的花费投入到算法侧,这样也可以找到智驾领域的突破口。
并且,算法的进步也可以让车端的算力大幅下降,比如Momenta只用了一颗Orin X+一个激光雷达,就可以跑城区NOA,还用一颗Orin N就能跑城区记忆领航,这跟前几年大家强调至少两颗Orin X才能用城区NOA、4颗Orin X更好的做法是完全不同的。

说完了软件层面的内容,我们再看看硬件。
智能座舱的硬件大家都已经知道,以前是8155,现在主要是8295P芯片。智能驾驶目前主要是英伟达的Orin X和Orin N芯片,还有中低端车型用地平线的J3。而在2025年的一个主流是:高端英伟达Thor;中端高通8650、英伟达Orin Y、地平线J6M;入门英伟达Orin N、地平线J6E,算力基本上是700TOPS、100-200TOPS、80TOPS级别。
但是从之后一段时间来看,硬件领域的变化主要是舱泊一体、舱驾一体的逻辑。现在车辆的电子电气架构都还是域控制为主,即便有中央集成式也往往是座舱域和智驾域,要分为两个部分,舱驾一体就是将两个域集成至一个计算单元中,共享一个高算力的单SoC。
这里面有两个主要的玩家,一个是英伟达,一个是高通。
英伟达主要是Thor芯片,已经在2025CES上发布了。虽然之前英伟达说Thor芯片算力是Orin X的8倍,但实际上是指算力最高的Thor X-Super版本,其实是还有1000TOPS的Thor X(预计Super就是两颗X合在一起)、750TOPS的Thor U、500TOPS的Thor S以及300TOPS的Z版本。

目前看极氪/领克首发的是Thor U系列,750TOPS算力,相当于之前的三颗Orin X性能,专门针对Transformer架构进行优化。而且整个算力可以根据需求划分,一部分给座舱、一部分给智驾,灵活性更高。
英伟达的优势主要是有自己更充分的生态系统绑定,甚至还升级为NVIDIA Drive OS,可以最大程度复用之前智驾解决方案。
高通方面会在今年推出SA8650系列的智驾芯片,算力可以满足100TOPS级别的纯视觉中阶智驾、也就是高速NOA,对标的也差不多就是英伟达今年会推出的中端版本——Orin X的继任者Orin Y。
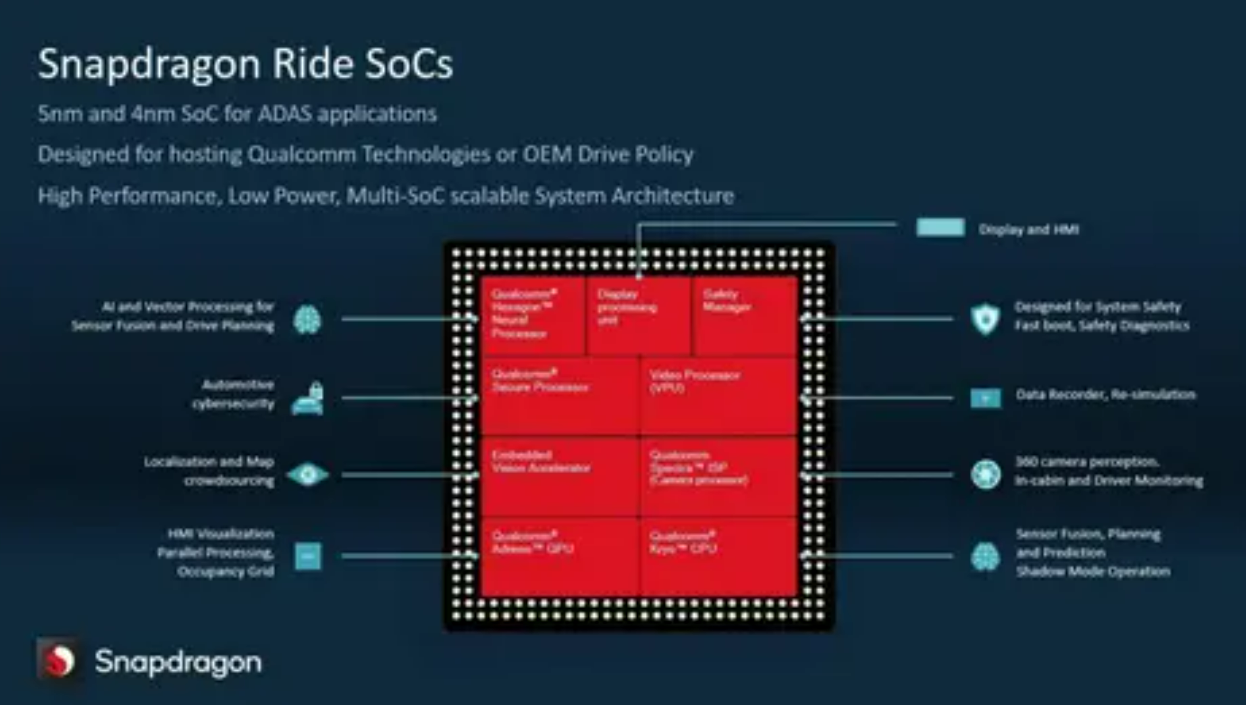
明年高通会推出舱泊一体方案,被称为Snapdragon Ride Flex SoC。第一款产品是8775芯片,大概是72TOPS的算力,也是可以座舱和智驾划分使用。但是从智驾30TOPS的算力来看,整个智驾能力也就是中端需求,主要满足高速NOA或者通勤NOA的需求,无法做到完全城市NOA。
不过高通这边主要是和供应商合作,包括大疆卓驭、Momenta、零跑这些,这样可以更好地推动传统车企使用,尤其是在中端产品上能够有比较好的智能座舱,以及及格线以上的智能驾驶。尤其是目前看卓驭已经有相关的方案在进行测试了,应该能做到一个比较不错的水平。
国内地平线也是一家可以做行泊一体方面的软硬件公司,目前地平线打造了征程6系列芯片,提供多达六款选择,算力覆盖10-560TOPS,可以实现所有市场需求。主流产品则是128TOPS的J6M芯片,已经定点给理想、比亚迪等多个领先车企。而且地平线还做了智驾软件SuperDrive,相当于软硬件都一起做,成为了智驾界的“Wintel”。由于地平线是一家中国公司,所以在国内新能源车企中很容易拿到定点,风险性远低于英伟达的高算力芯片。

当然,特斯拉又是另外一个故事了,特斯拉可以定制自己的芯片,现在特斯拉车型用的车载芯片叫做AI 4,其实就是HW 4.0。而AI5会在特斯拉无人驾驶出租车CyberCab上推出,之前马斯克说过AI5功耗会达到800W,猜测一下可能算力也会相比目前的产品提升四倍。
【PART 3:AI将如何改变汽车媒体】
最后花一点时间聊聊AI会如何改变驾仕派。从我个人来说,我现在可能有30%的精力放到了学习新的人工智能信息,尽可能掌握到汽车领域的新知识。
可能很多媒体认为学不学新知识无所谓,比如在燃油车到电动车的这几年好像内容也就这么做了,没有太大的区别。但是我个人认为,人工智能带来的差距不会说体现在你的内容表达上,而是会体现在你的工作效率上。AI本质上还是一件工具,如果你无法利用工具,那么你就会产生巨大的知识鸿沟,这样使你在媒体竞争中失去关注。
之前驾仕派在文章里面提到了两个词:
知识鸿沟(Knowledge Gap)
数字鸿沟(Digital divide)
知识鸿沟是说对事物的理解和判断出现了巨大的差距,而数字鸿沟是说在使用AI工具上的差距会带来更大的能力差距。两者叠加,就是有的人乘风而上,有的人可能就变成了很老派的人,无法融入新时代,而时代也不会搭理你。
从知识层面来看,如果确实不去学习什么是AI,什么是智驾,可能在一两年内感觉也不会有什么变化,该怎么说车、评车还是一样的,对于新奇的技术提一下就可以。
但是从长远来说,你没有办法给车企提供专业的建议,没有办法给新一代买车的年轻人提供更吸引他们的信息,你也不理解一线市场的需求,你没有办法判断一家车企的发展战略、没有办法理解一家车企的技术研发投入,最终你在这个行业也会被淘汰出去。因为你无法提供有思考价值的内容。
比如车企可能会问你,是自研智驾还是选择与华为合作,如果你回答智驾没有意义,我从来不用,那估计车企下一次也不会再问你,也不认为你有什么领先的价值。
从能力层面来看,如果汽车媒体不亲身入局去体验这些人工智能,还使用最传统、常规的方法做事情,效率上肯定跟不上。
比如我现在可以拿到一张销量榜,直接放到Kimi里面生成表格,在写一篇千字销量稿,大概只需要用5分钟。如果我们把一小时时长的播客放到AI里面去做总结,基本上10分钟就可以做出智能总结,然后再把要点筛选一下,可能半个小时就能发布播客。再多花半个小时,把AI整理出来的要点过一次,可能一篇包含各方观点的文章也就出来了。

AI现在带给我们的思考还是很多的。在2018年之前汽车垂媒如日中天,到2024年头部垂媒就已经和普通媒体没有本质区别了,都是字节系上内容贡献者,这个巨大的落差还是很明显的。
AI是一个工具,怎么用好是一个问题。这个问题需要我们一起去解决,但是现在要做的是大家先要去理解、体验什么是AI,要去尝试一些新的工具,而不是用老方法继续做事情。
最典型的一个例子我认为是,写稿子这件事情,原来写完就完了,发出去以后和我就无关了。但是在AI时代,一篇文章就是一个母内容,你可以把它做成播客,在录播客的时候可以放一个Pocket录坐播,甚至还能开一个直播。最后利用AI工具,视频做切片、音频发播客,一篇稿件还能分拆成短内容发小红书,这样就有了十倍的内容。
这就是AI带来的效率改变。
对于摄像剪辑也是一样的,AI时代变化很多,快速学习能力也是必不可少。有了AI功能,配字幕这个曾经很麻烦的一件事情,已经变成了很简单的一件事情,甚至AI都能够给你划出重点换成不同颜色。
同样在视频包装上,以前做个绿幕、遮罩很麻烦,但是现在AI加入之后都更容易,也可以做出很好的效果。还有就是AI可以重新整理脚本、整理分镜,都是可以帮助摄像剪辑们更好工作的。怎么样把这些内容在AI的帮助下用更简单的方式做得更好看,这些都是各位可以思考的。
当然,我们也要思考一些新设备带来的新体验和新改变,比如去年最火的AI眼镜,Meta Glass。本质上它更像是一个眼镜相机,可以拍摄更好的第一视角。同样今年有一家企业做了Xreal One这个设备,带来了随身便携的4K画质,所以这也会让我思考我们如何拍摄出让人更沉浸的内容,让内容可以更追随形式。还有就是苹果Vision Pro这个设备,虽然第一代显得比较失败,但是带来的内容重新思考却很重要,比如如何创新沉浸式的体验内容、表现形式如何更加生动,都是新体验设备会带来的改变。
总之,AI再厉害,也无法取代真正的体验。从驾仕派的角度来说,媒体要做的是,把真是的体验告诉给读者,把我们的认知告诉给我们的用户。媒体既然存在了千年,就意味着媒体一定有其不可替代的地方,我们要知道媒体的本质是什么,那就是要有敢为人先的体验,才能走在行业的前面,才会有读者追随。

可能很多人听到人工智能很陌生、感觉生活巨变觉得很遥远,但是就如同Autocarweekly的江小花老师说的,每一个人都要有一个锚点,在工作时不要只关注任务的完成,不知道自己作为汽车媒体到底要锚定什么核心点,这样发展的天花板就会很低。
所以,在这个AI推动世界巨变的新时代,我们需要有一个对AI的锚定,这样学习和理解很多新生事情其实就更有动力。我们才能够更好地和这个巨变的时代共振、能够始终矗立在潮头。
封面来自:即梦AI
(END)
全新岚图知音22万元起开启预售 8月底完成上市

在二手车交易市场中,信息不对称一直是困扰消费者的难题。近日,一则“46.2 万捡漏买下‘全损’特斯拉...

20万内最舒适豪华座舱来了!东风风神L8预售12.99万元起

在理想i8发布一周后,理想汽车(股票代码:“2015”)对理想i8产品进行了一番大调整。理想汽车以理想i8 Max作为标准配置,标配智能冷暖双用冰箱。

华为加码押注央企,「五界」表兄弟东风奕派科技上位!

赛车圈儿的竞赛事故我一般不放到网上讨论,毕竟“家丑不外扬”, 宣传比赛的魅力换来更多关注才是我们该做的。 但CTCC鄂尔多斯站后,东东的过激反应,让太多不关注赛车的朋友批评赛会,辱骂领克,这与事实严重不符。作为依靠“团队作战”赢了4届年度冠军的职业车手,作为一直吹捧自己以1敌5赢......

尊界S800车主:我是什么很贱的东西吗?

9.58万元起,没错这就是刚上市的,电混家轿的“颠覆者”,吉利银河A7。它可不是普通的电混家轿——它是带着“颜值暴击”和“五大颠覆”来掀桌子的!


如果你对越野满怀热忱,那芦芽山的名字你必定不陌生。 此次【胖哥游记】中,胖哥将携手《越玩越野》大唐,在因暴雨而难度陡增的芦芽山开启一场惊险刺激的密林穿越,等待他们的会是什么境遇呢?本周五正片准时上线,我们一起拭目以待。(特别鸣谢:运良越野)

空间够大配置高?别克新君越静态体验!一口价香爆了?

8月13日,15万级唯一全系标配华为乾崑智驾轿车——2026款深蓝L07焕新上市,共推出6个版本,售价区间为13.59-15.59万元。

最近车市热闹非凡,乐道 L90 上市 10 天交付超 4 千台,成绩亮眼。与此同时,极狐新阿尔法 T5 也带着诸多亮点闯入大家视野。

埃安UT推加码育儿补贴,三岁萌娃也能月入过万

为何电动自行车灯光普遍刺眼,难道司机们都不知道会车开近光吗?

天才不可怕,可怕的是努力的天才

为给育儿家庭实现普惠式减负,7月28日国家发布了育儿补贴方案,全国3岁以下婴幼儿每年可领3600元,至其年满3周岁,最高可领10800元。政策一经推出便受到了宝妈人群的广泛关注。与此同时,给家里增加一台车也成为了当下有娃家庭的刚需。

4S店售后业务外包成为常态,捆绑售后的质保还有意义吗?

极端罕见场景大考验!蔚来ES6如何应对?主动安全立大功?

为何燃油车的空调感觉更冷,电动汽车空调感觉过于温和?






































 京公网安备 11010102004670号
京公网安备 11010102004670号